© Copyright 2020-2022 the original author or authors.
This is the Neo4j-Migrations manual version 1.4.0.
1. Introduction
1.1. About
Neo4j-Migrations are a set of tools to make your schema migrations as easy as possible. They provide a uniform way for applications, the command line and build tools alike to track, manage and apply changes to your database, in short: to refactor your database. The project is inspired to a large extend by FlywayDB, which is an awesome tool for migration of relational databases. Most things evolve around Cypher scripts, however the Core API of Neo4j-Migrations allows defining Java classes as migrations as well.
Neo4j-Migrations builds directly on top of the official Neo4j Java driver, supports Neo4j from 3.5 up to 4.4, including enterprise features such as multidatabase support and impersonation. The only dependencies are said driver and ClassGraph, the latter being used to find migrations on the classpath.
The history of migrations applied is stored as a subgraph in your database.
1.2. Compatibility
Neo4j-Migrations is tested only against Neo4j, the world’s leading Graph database. Neo4j-Migrations requires a 4.x version of Neo4j Java Driver. The project is build and tested with the latest 4.4 version, however previous versions 4.3, 4.2 and 4.1 are supported as well and can be used as drop-in-replacement. Therefore, Neo4j-Migrations works with Neo4j 3.5, 4.0 - 4.4 and of course, Neo4j-Aura. It also can be used with an embedded instance, as long as the embedded instances provides the Bolt-Connector, too. The tooling may or may not work with other databases using the Bolt protocol. We don’t provide any support for those.
The Core API and the JVM based version of the CLI module of Neo4j-Migrations requires at least Java 8 to run. Native binaries are provided for 64bit versions of macOS, Linux and Windows. The native binaries don’t require a JVM to be installed.
All releases of Neo4j-Migrations are compiled with JDK 17 while targeting JDK 8. Thus, we ensure both source, target and API compatibility with JDK 8.
In addition, the Core API is provided as a Multi-Release-Jar, providing a module-info.java for JDK 11 and higher, making it a good citizen on the Java module path.
For JDK 17 and higher we do restrict the usage of some interfaces and have better boundaries for you what you can safely implement and what you should not.
1.3. Versions
Neo4j-Migrations 1.0.0 has been considered stable and has been released in November 2021. Since then, we ensure semantic versioning. This means in cases where you use the Java API directly, you can be sure that patch releases won’t break your application, and you can always upgrade.
1.4. Modules
Neo4j-Migrations comes in different flavors:
- Core
-
The core module, providing an API to run both Cypher script and Java-based migrations. The API includes builders for configuration. The core is released as a Multi-Release-Jar, so that it behaves nicely on the module-path on JDK 17. Be aware that we sealed all interfaces not intended to be implemented by you when running on JDK 17.
JavaDoc and Project info
- CLI
-
A command line tool that supports every interaction that the core module provides. Native binaries are available for Linux, macOS and Windows. If you want to use Java-based migrations in the CLI, you must use the JVM distribution. This is an ideal tool to be put into CI/CD not based on Maven or Gradle.
- Spring-Boot-Starter
-
Provides all configuration options via the well-known Spring-Boot-Properties mechanism and turns them into a fully configured Migrations instance that will be applied on application start. Scripts will be searched sane default location.
JavaDoc and Project info
- Quarkus
-
An extension for Quarkus, providing full integration of all configuration option via Quarkus' configuration. Creates a startup observer that applies all resolved migrations at startup.
JavaDoc and Project info
- Maven-Plugin
-
A Maven-plugin that hooks clean, apply and verify operations into the appropriate Maven lifecycles. Use this to apply migrations during your build.
1.5. Changelog
We provide a full changelog on GitHub: Neo4j-Migrations. Our commits follow conventional commits. The releases are created and published via JReleaser.
1.6. History
The original idea of Neo4j-Migrations was conceived when working on integrating Spring Data Neo4j (back then SDN/RX) into JHipster. We needed some Nodes, constraints and relationship to be present in the Neo4j database for JHipster to do it’s magic but back then there was no lightweight (in terms of dependencies) tool that did work well with Neo4j 4.0 (the first Graph database providing reactive data access out of the box). Neo4j-Migrations filled that gap in early 2020 and has grown ever since.
2. Download
2.1. CLI
2.1.1. For homebrew users on macOS
brew install michael-simons/homebrew-neo4j-migrations/neo4j-migrationsAutocompletion is automatically installed and available for bash and zsh when you configured Homebrew accordingly.
2.1.2. Linux
As download from our release page:
curl -LO https://github.com/michael-simons/neo4j-migrations/releases/download/1.4.0/neo4j-migrations-1.4.0-linux-x86_64.zip2.1.3. Windows
As download from our release page:
curl -LO https://github.com/michael-simons/neo4j-migrations/releases/download/1.4.0/neo4j-migrations-1.4.0-windows-x86_64.zip2.1.4. Architecture independent
In addition to the above native binaries we still offer a JVM, architecture independent version of Neo4j-Migrations-CLI.
Only the JVM version does support custom, Java-based migrations as shown via the argument --package, the natively compiled versions do not.
Get this version here:
curl -LO https://github.com/michael-simons/neo4j-migrations/releases/download/1.4.0/neo4j-migrations-1.4.0.zip|
The architecture independent version can be used via Neo4js official JBang catalog:
With JBang installed, run jbang neo4j-migrations@neo4j --help for printing our usage information.
The catalog offers a couple of other scripts as well, check them out with jbang catalog list neo4j.
|
2.2. Core API
The easiest way to get the Core API is to use a build- and dependency-management tool like Maven or Gradle. Here are the coordinates:
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations</artifactId>
<version>1.4.0</version>
</dependency>Or in case you fancy Gradle:
dependencies {
implementation 'eu.michael-simons.neo4j:neo4j-migrations:1.4.0'
}2.3. Spring-Boot-Starter
Use your dependency management to include the Spring-Boot-Starter.
The starter automatically triggers the dependency to the Neo4j-Java-Driver, which than can be configured via properties in the spring.neo4j.* namespace.
This starter here has a custom namespace, please refer to Section 4.4 for more information.
<dependencies>
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-spring-boot-starter</artifactId>
<version>1.4.0</version>
</dependency>
</dependencies>Or in case you fancy Gradle:
dependencies {
implementation 'eu.michael-simons.neo4j:neo4j-migrations-spring-boot-starter:1.4.0'
}2.4. Quarkus
Use your dependency management to include the Quarkus extension.
This extension automatically triggers the dependency to the Neo4j extension containing the Neo4j-Java-Driver.
The latter can be configured via properties in the quarkus.neo4j.* namespace.
The namespace for this extension is also org.neo4j.migrations.*.
<dependencies>
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-quarkus</artifactId>
<version>1.4.0</version>
</dependency>
</dependencies>2.5. Maven-Plugin
Include the Maven-Plugin like this in your build and configure it according to Section 4.6:
<plugins>
<plugin>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-maven-plugin</artifactId>
<version>1.4.0</version>
<configuration>
<user>neo4j</user>
<password>secret</password>
<address>bolt://localhost:${it-database-port}</address>
<verbose>true</verbose>
</configuration>
<executions>
<execution>
<id>migrate</id>
<goals>
<goal>migrate</goal>
</goals>
</execution>
<execution>
<id>default-validate</id>
<goals>
<goal>validate</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>3. Concepts
This chapter deals with various concepts that are applicable for all modules offered. Especially checkout Section 3.4 regarding naming conventions, for all Cypher and Java-based migrations and callbacks.
3.1. Connectivity
Neo4j-Migrations solely uses the Neo4j Java Driver.
Most of the time you pass a pre-configured driver object to our API.
The Spring-Boot-Plugin depends on the driver-instance provided by Spring-Boot which can be configured via properties in the spring.neo4j.* space.
The CLI and Maven-Plugin offer parameters to define the URL, username and password alike.
All of this mean that we can keep this chapter short and basically defer to the driver’s documentation:
The Neo4j Java Driver Manual v4.4.
For ease of use, here are the most common forms of URLs the driver might take.
The URLS all have this format: <NEO4J_PROTOCOL>://<HOST>:<PORT>.
The Neo4j-Protocol might be one of the following:
| URI scheme | Routing | Description |
|---|---|---|
|
Yes |
Unsecured |
|
Yes |
Secured with full certificate |
|
Yes |
Secured with self-signed certificate |
|
No |
Unsecured |
|
No |
Secured with full certificate |
|
No |
Secured with self-signed certificate |
You don’t have to care much more about the Driver API than knowing how to create an instance:
import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Config;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
class HowToCreateADriverInstance {
public static void main(String... args) {
Driver driver = GraphDatabase.driver(
"neo4j://your.database.io",
AuthTokens.basic("neo4j", "secret"),
Config.defaultConfig()
);
}
}This instance needs to be passed than to the Neo4j-Migrations Core API in case you aren’t using one of our integrations. Mostly everything else than can be done via Cypher scripts alone. If you need more control about what happens in a migration, have a look at our Java-based migration support in Section 3.2.2.
3.2. Migrations
Migrations are all operations or refactorings you apply to a database. These operations might be creating, changing, or dropping indexes and constraints or altering data. Sometimes you might even want to create users or databases.
3.2.1. Cypher-based
Cypher-based migrations can be mostly anything you can write down as Cypher statement.
A Cypher-based migration can contain one or more statements with multiple lines separated by a ; followed by a new line.
By default, all statements in one script will be executed in a single transaction.
Here’s an example:
CREATE (agent:`007`) RETURN agent;
UNWIND RANGE(1,6) AS i
WITH i CREATE (n:OtherAgents {idx: '00' + i})
RETURN n
;This script contains two different statements.
Neo4j-Migrations will by default look in classpath:neo4j/migrations for all *.cypher files matching the name described in
Section 3.4. You can change (or add to this default) with the Core API or the appropriate properties in
Spring-Boot-Starter or the Maven-Plugin like this:
MigrationsConfig configLookingAtDifferentPlaces = MigrationsConfig.builder()
.withLocationsToScan(
"classpath:my/awesome/migrations", (1)
"file:/path/to/migration" (2)
).build();| 1 | Look at a different place on the classpath |
| 2 | Look additional at the given filesystem path |
Switching database inside Cypher scripts
It is of course possible to use the Cypher keyword USE <graph> (See USE) inside your scripts.
There a couple of thinks to remember, though:
-
It can get tricky if you combine it in creative ways with the options for schema- and target-databases Neo4j-Migrations offer itself
-
If you have more than one statement per script (which is completely not a problem) and one of them should use
USEyou must configure Neo4j-Migrations to useTransactionMode#PER_STATEMENT(see Section 3.7, meaning to run each statement of a script in a separate transaction. This is slightly more error-prone, as it will most likely leave your database in an inconsistent state if one statement fails, since everything before has already been committed.
3.2.2. Java-based
Neo4j-Migrations provides the interface ac.simons.neo4j.migrations.core.JavaBasedMigration for you to implement.
Based on that interface you can do much more than just migrate things via adding or changing data:
You can refactor everything in your database in a programmatic way.
One possible migration looks like this:
package some.migrations;
import ac.simons.neo4j.migrations.core.JavaBasedMigration;
import ac.simons.neo4j.migrations.core.MigrationContext;
import org.neo4j.driver.Driver;
import org.neo4j.driver.Session;
public class V001__MyFirstMigration implements JavaBasedMigration {
@Override
public void apply(MigrationContext context) {
try (Session session = context.getSession()) { (1)
// Steps necessary for a migration
}
}
}| 1 | The MigrationContext provides both getSession() or getSessionConfig() to be used in combination with getDriver().
The latter is helpful when you want to have access to a reactive or asynchronous session.
It is important that you use the convenient method getSession() or create a session with the provided config as only
those guarantee hat your database session will be connected to the configured target database with the configured user.
In addition, our context will take care of managing Neo4j causal cluster bookmarks.
However, if you feel like it is necessary to switch to a different database, you can use the driver instance any way you want.
The transaction handling inside Java-based migrations is completely up to you. |
You don’t have to annotate your Java-based migrations in any way. Neo4j-Migrations will find them on the classpath as is. The same naming requirements that apply to Cypher scripts apply to Java-based migrations as well, see Section 3.4.
|
There are some restrictions when it comes to run Neo4j-Migrations on GraalVM native image:
You might or might not be able to convince the runtime to find implementations of an interface in native image.
You must at least explicitly include those classes in the native image unless used otherwise as well.
The CLI will outright refuse to scan for Java-based migrations in its native form (when using the --package option).
It does support them only in JVM mode.
|
While you can theoretically extend the public base interface Migration too, we don’t recommend it.
In fact, on JDK 17 we forbid it.
Please use only JavaBasedMigration as the base interface for your programmatic migrations.
3.3. Callbacks
Callbacks are part of a refactoring or a chain of migration that lives outside the chain of things.
As such these callbacks can be used to make sure certain data, constructs or other preconditions are available or fulfilled before anything else happens.
They also come in handy during integration tests.
You might want to have your migrations as part of the main source tree of your application and
at the same time have in your tests source tree the same folder with a bunch of callbacks that
create test data for example in an afterMigrate event.
Callbacks are not considered immutable after they have been invoked and their invocation is not stored in the history graph. This gives you a hook to add some more volatile things to your refactoring.
The beforeFirstUse callback is especially handy in cases in which you want to create the target database before migrations
are applied: It will always be invoked inside the home database of the connected user, so at this point, the target database
does not need to exist yet.
3.3.1. Lifecycle phases
The following phases are supported:
- beforeFirstUse
-
The only phase that only runs once for any given instance of Neo4j-Migrations. It will run before any other operations are called, when the first connection is opened. Callbacks in this phase will always be invoked in the schema database and not the target database, so they won’t require the target database to be present. Also, no user impersonation will be performed. This can be used to create the target database before any migrations or validations are run.
- beforeMigrate
-
Before migrating a database.
- afterMigrate
-
After migrating a database, independent of outcome.
- beforeClean
-
Before cleaning a database.
- afterClean
-
After cleaning a database, independent of outcome.
- beforeValidate
-
Before validating a database.
- afterValidate
-
After validating a database, independent of outcome.
- beforeInfo
-
Before getting information about the target database.
- afterInfo
-
After getting information about the target database.
3.4. Naming conventions
3.4.1. Cypher-based resources
All Cypher-based resources (especially migration and callback scripts) require .cypher as extension.
The Core API, the Spring-Boot-Starter and the Maven-Plugin will by default search for such Cypher scripts in classpath:neo4j/migrations.
The CLI has no default search-location.
Migration scripts
A Cypher script based migration must have a name following the given pattern to be recognized:
V1_2_3__Add_last_name_index.cypher-
Prefix
Vfor "Versioned Migrations" -
Version with optional underscores separating as many parts as you like
-
Separator:
__(two underscores) -
Required description: Underscores or spaces might be used to separate words
-
Suffix:
.cypher
This applies to both Cypher scripts outside an application (in the file system) and inside an application (as resources).
| Cypher-based migrations scripts are considered to be immutable once applied! We compute their checksums and record it inside the schema database. If you change a Cypher-based migration after it has been applied, any further application will fail. |
Callback scripts
A Cypher script is recognized as a callback for a given lifecycle if it matches the following pattern:
nameOfTheLifecyclePhase.cypher
nameOfTheLifecyclePhase__optional_description.cyphernameOfTheLifecyclePhase must match exactly (case-sensitive) the name of one of the supported lifecycle phases (see Section 3.3.1),
followed by an optional description and the suffix .cypher, separated from the name of the phase by two underscores (__).
The description is used to order different callback scripts for the same lifecycle phase.
If you use more than one script in the same lifecycle phase without a description, the order is undefined.
Callback scripts are not considered to be immutable and can change between execution.
If you use DDL statements such as CREATE USER or CREATE DATABASE in them make sure you look for an IF NOT EXITS
option in your desired clause so that these statements become idempotent.
|
3.4.2. Java-based migrations
For Java (or actually anything that can be compiled to a valid Java class) based migrations, the same naming conventions apply as for
Cypher-based scripts apart from the extension.
To stick with the above example, V1_2_3__Add_last_name_index.cypher becomes V1_2_3__Add_last_name_index as simple class name,
or in source form, V1_2_3__Add_last_name_index.java.
Our recommendation is to use something like this:
public class V1_2_3__AddLastNameIndex implements JavaBasedMigration {
@Override
public void apply(MigrationContext context) {
// Your thing
}
@Override
public String getSource() {
return "Add last name index"; (1)
}
}| 1 | Defaults to the simple class name being added to the history chain. |
3.5. Chain of applied migrations
All migrations applied to a target database are stored in the schema database. The target and the schema database can be the same database. If you are an enterprise customer managing different databases for different tenants that are however used for the same application, it makes absolutely sense to use a separate schema database that stores all data related to Neo4j-Migrations.
The subgraph will look like this:
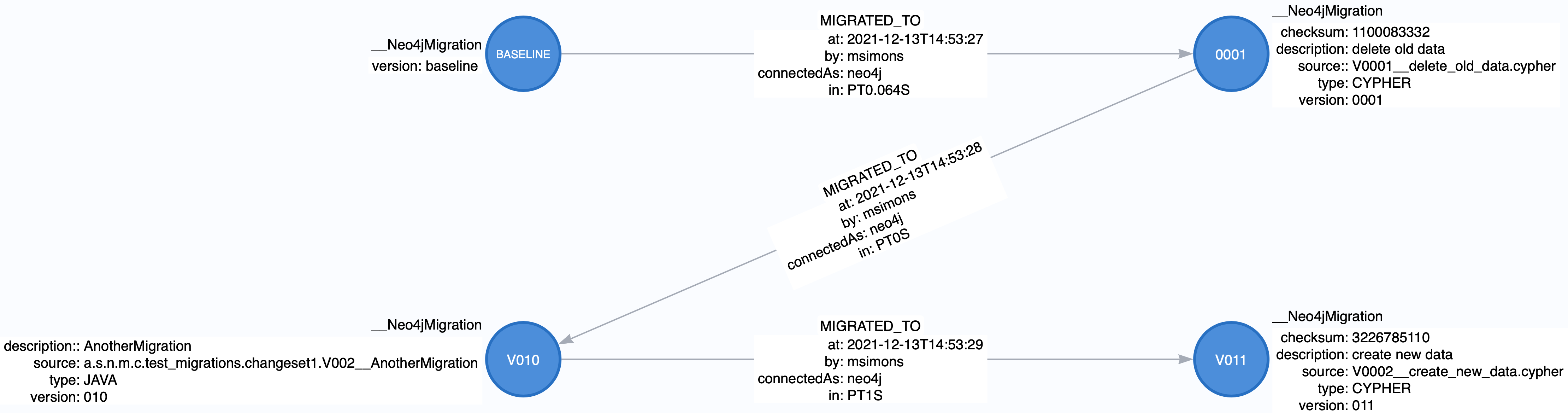
In case you use a schema database for any database with a different name than the default (which is neo4j) the nodes
labelled __Neo4jMigration will have an additional property name migrationTarget which contains the target graph.
3.6. Separate schema databases
Since version 1.1.0 you can use a different database for storing information about migrations.
You need to run a Neo4j 4+ Enterprise Edition.
The command line argument and the property, respectively, is schema-database throughout the configuration.
The name given must be a valid Neo4j database name (See Administration and configuration).
The database must exist and the user must have write access to it.
Valid scenarios are:
-
Using a schema database for one other database
-
Using a schema database for maintaining multiple migrations of different databases
-
Using pairs of schema databases and target databases
Neo4j-Migrations will create subgraphs in the schema database identifiable by a migrationTarget-property in the __Neo4jMigration-nodes.
Neo4j-Migrations will not record a migrationTarget for the default database (usually neo4j),
so that this feature doesn’t break compatibility with schemas created before 1.1.0.
3.7. Transactions
All operations executed directly by Neo4j-Migrations are executed inside transactional functions. This is essentially a scope around one or more statements which will be retried on certain conditions (for example, on losing connectivity inside a cluster setup).
You can configure if all statements of one Cypher-based migration go into one transactional function or if each statement goes into its own transactional scope:
MigrationsConfig configPerMigration = MigrationsConfig.builder()
.withTransactionMode(MigrationsConfig.TransactionMode.PER_MIGRATION)
.build();
// OR
MigrationsConfig configPerStatement = MigrationsConfig.builder()
.withTransactionMode(MigrationsConfig.TransactionMode.PER_STATEMENT)
.build();Per Migration is the default, as we think it’s safer: Either the whole migration is applied (or failed) or none. But there are certain scenarios that require a transaction per statement, for example most DDL operations such as creating databases might not be run together with DML operations in the same transaction.
4. Usage
4.1. Common operations
4.1.1. Clean
clean applies by default to the schema database.
It will remove Neo4j-Migrations related nodes and relationships.
If there is no schema database selected, it works on the optional target database.
If this isn’t configured either, the users home database will be used.
The clean operation will search for
-
Migration chains (those are the nodes containing information about the applied migrations)
-
Any log from this Neo4j-Migrations
-
Any constraints created by Neo4j-Migrations
and will delete and drop them in that order. This is a destructive operation, so make sure not to apply it to your production database without thinking at least twice. It cannot be undone via Neo4j-Migrations.
The operation takes in a boolean parameter.
When set to false, only the migration chain for the currently configured target database will be deleted.
When set to true, all objects created by Neo4j-Migrations will be deleted.
4.1.2. Info
The info operations returns information about the context, the database, all applied and all pending applications.
4.1.3. Migrate / apply
The migrate command (or its underlying method apply in the Migrations Core API) does exactly that:
It applies all locally resolved migrations to the target database and stores the chain of applied migrations in the schema database.
It returns the last applied version.
4.1.4. Validate
The validate operations resolves all local migrations and checks whether all have applied in the same order and in the
same version to the configured database.
A target database will validate as valid when all migrations have been applied in the right order and invalid in any cases
where migrations are missing, have not been applied, applied in a different order or with a different checksum.
The validation result provides an additional operation needsRepair().
In case the result is invalid you might check if it needs repair.
If not, you can just call the apply operation to turn the database into a valid state.
4.2. CLI
Please choose the version of Neo4j-Migrations-CLI fitting your operating system or target system as described in Section 2.1. In the following we assume you downloaded and unzipped the architecture independent version. For that version to work, you need to have JDK 8 or higher installed:
java -version
curl -LO https://github.com/michael-simons/neo4j-migrations/releases/download/1.4.0/neo4j-migrations-1.4.0.zip
unzip neo4j-migrations-1.4.0.zip
cd neo4j-migrations-1.4.0
./bin/neo4j-migrations -VThose commands should first print out your Java version, then download, extract and run Neo4j-Migrations-CLI to give you its version.
| If you only deal with Cypher-based migrations and don’t have the need for any programmatic migrations, we provide a native binary for your platform, make sure to choose that. Its startup time is faster, and you don’t need to have a JVM installed. |
4.2.1. All options and arguments
The CLI comes with a build-in help, accessible via neo4j-migrations -h or neo4j-migrations --help:
./bin/neo4j-migrations --help
Usage: neo4j-migrations [-hvV] [--autocrlf] [--validate-on-migrate] -p
[=<password>] [-p[=<password>]]... [-a=<address>]
[-d=<database>] [--impersonate=<impersonatedUser>]
[--schema-database=<schemaDatabase>]
[--transaction-mode=<transactionMode>] [-u=<user>]
[--location=<locationsToScan>]...
[--package=<packagesToScan>]... [COMMAND]
Migrates Neo4j databases.
-a, --address=<address> The address this migration should connect to. The
driver supports bolt, bolt+routing or neo4j as
schemes.
--autocrlf Automatically convert Windows line-endings (CRLF)
to LF when reading resource based migrations,
pretty much what the same Git option does during
checkin.
-d, --database=<database> The database that should be migrated (Neo4j EE 4.0
+).
-h, --help Show this help message and exit.
--impersonate=<impersonatedUser>
The name of a user to impersonate during migration
(Neo4j EE 4.4+).
--location=<locationsToScan>
Location to scan. Repeat for multiple locations.
-p, --password[=<password>]
The password of the user connecting to the database.
--package=<packagesToScan>
Package to scan. Repeat for multiple packages.
--schema-database=<schemaDatabase>
The database that should be used for storing
information about migrations (Neo4j EE 4.0+).
--transaction-mode=<transactionMode>
The transaction mode to use.
-u, --username=<user> The login of the user connecting to the database.
-v Log the configuration and a couple of other things.
-V, --version Print version information and exit.
--validate-on-migrate Validating helps you verify that the migrations
applied to the database match the ones available
locally and is on by default.
Commands:
clean Removes Neo4j-Migration specific data from the selected
schema database
help Displays help information about the specified command
info Retrieves all applied and pending informations, prints them
and exits.
init Creates a migration project inside the current folder.
migrate, apply Retrieves all pending migrations, verify and applies them.
validate Resolves all local migrations and validates the state of the
configured database with them.If no values are given to either location or packages we check for a directory structure of neo4j/migrations inside
the current working directory and use that as a default for location if such a structure exists.
The info command takes a mode option as an optional argument:
Usage: neo4j-migrations info [mode=<mode>]
Retrieves all applied and pending informations, prints them and exits.
mode=<mode> Controls how the information should be computed. Valid
options are COMPARE, LOCAL, REMOTE with COMPARE being the
default. COMPARE will always compare locally discovered
and remotely applied migrations, while the other options
just check what's there.
This means that we by default compare what has been discovered locally with what has been applied in the database:
We check for missing or superfluous migrations and also compare checksums.
At times, you might want to have just a quick look at what is in the database, without configuring a local filesystem.
Use mode=remote in that case: We just look at what is in the database and assume everything is applied.
Use mode=local to print out what has been discovered locally with the current settings and would be applied to an empty database.
neo4j-migrations looks in the current working directory for a properties file called .migration.properties which
can contain all supported options. Use such a file to avoid repeating long command lines all the time.
Use neo4j-migrations init to create a file with the default values. Any options passed to neo4j-migrations before
the init command will also be store.
|
4.2.2. Safe passwords in CI/CD usage
There are 4 ways to specify the password:
-
interactive: Use
--passwordwithout arguments and your shell will prompt you with a hidden prompt. -
direct: Use
--password not-so-secret. The password will be visible in the shell history and in the process monitor. -
Via environment variable: Define an environment variable like
MY_PASSWORDand use--password:env MY_PASSWORD. Note that the parameter is the name of the variable, not the resolved value. -
Via a file: Create a file in a safe space and add your password in a single line in that file and use
--password:file path/to/your/passwordFile. The password will be read from this file.
The last two options are a safe choice in scripts or in a CI/CD environment.
4.2.3. Enable autocompletion for Neo4j-Migrations in your shell
Neo4j-Migrations can generate a shell script providing autocompletion for its options in Bash, zsh and others. Here’s how to use it:
./bin/neo4j-migrations generate-completion > neo4j-migrations_completion.shThe generated script neo4j-migrations_completion.sh can than be run via . neo4j-migrations_completion.sh or permanently installed by
sourcing it in your ~/.bashrc or ~/.zshrc.
If you want to have autocompletion for Neo4j-Migrations just in your current shell use the following command
source <(./bin/neo4j-migrations generate-completion)| Autocompletion for macOS is automatically installed when you use Homebrew. |
4.2.4. Full example
Here’s an example that looks for migrations in a Java package, its subpackages and in a filesystem location for Cypher-based migrations.
In this example we have exported the directory with our Java-based migrations like this: export CLASSPATH_PREFIX=~/Projects/neo4j-migrations/neo4j-migrations-core/target/test-classes/.
Please adapt accordingly to your project and / or needs.
The example uses the info command to tell you which migrations have been applied and which not:
./bin/neo4j-migrations -uneo4j -psecret \
--location file:$HOME/Desktop/foo \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset1 \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset2 \
info
neo4j@localhost:7687 (Neo4j/4.4.0)
Database: neo4j
+---------+-----------------------------+--------+--------------+----+----------------+---------+--------------------------------------------------------------+
| Version | Description | Type | Installed on | by | Execution time | State | Source |
+---------+-----------------------------+--------+--------------+----+----------------+---------+--------------------------------------------------------------+
| 001 | FirstMigration | JAVA | | | | PENDING | a.s.n.m.c.t.changeset1.V001__FirstMigration |
| 002 | AnotherMigration | JAVA | | | | PENDING | a.s.n.m.c.t.changeset1.V002__AnotherMigration |
| 023 | NichtsIstWieEsScheint | JAVA | | | | PENDING | a.s.n.m.c.t.changeset2.V023__NichtsIstWieEsScheint |
| 023.1 | NichtsIstWieEsScheintNeu | JAVA | | | | PENDING | a.s.n.m.c.t.changeset2.V023_1__NichtsIstWieEsScheintNeu |
| 023.1.1 | NichtsIstWieEsScheintNeuNeu | JAVA | | | | PENDING | a.s.n.m.c.t.changeset2.V023_1_1__NichtsIstWieEsScheintNeuNeu |
| 030 | Something based on a script | CYPHER | | | | PENDING | V030__Something_based_on_a_script.cypher |
| 042 | The truth | CYPHER | | | | PENDING | V042__The truth.cypher |
+---------+-----------------------------+--------+--------------+----+----------------+---------+--------------------------------------------------------------+You can repeat both --package and --location parameter for fine-grained control.
Use migrate to apply migrations:
./bin/neo4j-migrations -uneo4j -psecret \
--location file:$HOME/Desktop/foo \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset1 \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset2 \
migrate
Applied migration 001 ("FirstMigration")
Applied migration 002 ("AnotherMigration")
Applied migration 023 ("NichtsIstWieEsScheint")
Applied migration 023.1 ("NichtsIstWieEsScheintNeu")
Applied migration 023.1.1 ("NichtsIstWieEsScheintNeuNeu")
Applied migration 030 ("Something based on a script")
Applied migration 042 ("The truth")
Database migrated to version 042.If we go back to the info example above and grab all migrations again, we find the following result:
./bin/neo4j-migrations -uneo4j -psecret \
--location file:$HOME/Desktop/foo \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset1 \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset2 \
info
Database: Neo4j/4.0.0@localhost:7687
+---------+-----------------------------+--------+-------------------------------+---------------+----------------+---------+--------------------------------------------------------------+
| Version | Description | Type | Installed on | by | Execution time | State | Source |
+---------+-----------------------------+--------+-------------------------------+---------------+----------------+---------+--------------------------------------------------------------+
| 001 | FirstMigration | JAVA | 2021-12-14T12:16:43.577Z[UTC] | msimons/neo4j | PT0S | APPLIED | a.s.n.m.c.t.changeset1.V001__FirstMigration |
| 002 | AnotherMigration | JAVA | 2021-12-14T12:16:43.876Z[UTC] | msimons/neo4j | PT0.032S | APPLIED | a.s.n.m.c.t.changeset1.V002__AnotherMigration |
| 023 | NichtsIstWieEsScheint | JAVA | 2021-12-14T12:16:43.993Z[UTC] | msimons/neo4j | PT0S | APPLIED | a.s.n.m.c.t.changeset2.V023__NichtsIstWieEsScheint |
| 023.1 | NichtsIstWieEsScheintNeu | JAVA | 2021-12-14T12:16:44.014Z[UTC] | msimons/neo4j | PT0S | APPLIED | a.s.n.m.c.t.changeset2.V023_1__NichtsIstWieEsScheintNeu |
| 023.1.1 | NichtsIstWieEsScheintNeuNeu | JAVA | 2021-12-14T12:16:44.035Z[UTC] | msimons/neo4j | PT0S | APPLIED | a.s.n.m.c.t.changeset2.V023_1_1__NichtsIstWieEsScheintNeuNeu |
| 030 | Something based on a script | CYPHER | 2021-12-14T12:16:44.093Z[UTC] | msimons/neo4j | PT0.033S | APPLIED | V030__Something_based_on_a_script.cypher |
| 042 | The truth | CYPHER | 2021-12-14T12:16:44.127Z[UTC] | msimons/neo4j | PT0.011S | APPLIED | V042__The truth.cypher |
+---------+-----------------------------+--------+-------------------------------+---------------+----------------+---------+--------------------------------------------------------------+Another migrate - this time with all packages - gives us the following output and result:
./bin/neo4j-migrations -uneo4j -psecret \
--location file:$HOME/Desktop/foo \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset1 \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset2 \
migrate
Skipping already applied migration 001 ("FirstMigration")
Skipping already applied migration 002 ("AnotherMigration")
Skipping already applied migration 023 ("NichtsIstWieEsScheint")
Skipping already applied migration 023.1 ("NichtsIstWieEsScheintNeu")
Skipping already applied migration 023.1.1 ("NichtsIstWieEsScheintNeuNeu")
Skipping already applied migration 030 ("Something based on a script")
Skipping already applied migration 042 ("The truth")
Database migrated to version 042.The database will be now in a valid state:
./bin/neo4j-migrations -uneo4j -psecret \
--location file:$HOME/Desktop/foo \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset1 \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset2 \
validate
All resolved migrations have been applied to the default database.4.2.5. A template for Java-based migrations
As stated above, this will work only with the JVM distribution. Follow those steps:
wget https://github.com/michael-simons/neo4j-migrations/releases/download/1.4.0/neo4j-migrations-1.4.0.zip
unzip neo4j-migrations-1.4.0.zip
cd neo4j-migrations-1.4.0
mkdir -p my-migrations/some/migrations
cat <<EOT >> my-migrations/some/migrations/V001__MyFirstMigration.java
package some.migrations;
import ac.simons.neo4j.migrations.core.JavaBasedMigration;
import ac.simons.neo4j.migrations.core.MigrationContext;
import org.neo4j.driver.Driver;
import org.neo4j.driver.Session;
public class V001__MyFirstMigration implements JavaBasedMigration {
@Override
public void apply(MigrationContext context) {
try (Session session = context.getSession()) {
}
}
}
EOT
javac -cp "lib/*" my-migrations/some/migrations/*
CLASSPATH_PREFIX=my-migrations ./bin/neo4j-migrations -v -uneo4j -psecret --package some.migrations info| We do add this here for completeness, but we do think that Java-based migrations makes most sense from inside your application, regardless whether it’s a Spring Boot, Quarkus or just a plain Java application. The CLI should be seen primarily as a script runner. |
4.3. Core API
We publish the Java-API-Docs here: Neo4j Migrations (Core) 1.4.0 API. Follow the instructions for your favorite dependency management tool to get hold of the core API as described in Section 2.2.
The classes you will be working with are ac.simons.neo4j.migrations.core.MigrationsConfig and its related builder and
ac.simons.neo4j.migrations.core.Migrations and maybe ac.simons.neo4j.migrations.core.JavaBasedMigration in case you
want to do programmatic refactorings.
4.3.1. Configuration and usage
Configuration is basically made up of two parts:
Creating a driver instance that points to your database or cluster as described in Section 3.1 and an instance of MigrationsConfig.
An instance of MigrationsConfig is created via a fluent-builder API.
Putting everything together looks like this:
Migrations based on a configuration object and the Java driverMigrations migrations = new Migrations(
MigrationsConfig.builder()
.withPackagesToScan("some.migrations")
.withLocationsToScan(
"classpath:my/awesome/migrations",
"file:/path/to/migration"
)
.build(),
GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "secret"))
);
migrations.apply(); (1)| 1 | Applies this migration object and migrates the database |
In case anything goes wrong the API will throw a ac.simons.neo4j.migrations.core.MigrationsException.
Of course your migrations will be recorded as a chain of applied migrations (as nodes with the label __Neo4jMigration) as well when you use the API directly.
4.3.2. Running on the Java module-path
Neo4j-Migrations can be used on the Java module path. Make sure you require them in your module and export packages with Java-based migrations in case you’re using the latter. Resoruces on the classpath should be picked up automatically:
module my.module {
requires ac.simons.neo4j.migrations.core;
exports my.module.java_based_migrations; (1)
}| 1 | Only needed when you actually have those |
4.4. Spring-Boot-Starter
We provide a starter with automatic configuration for Spring Boot. Declare the following dependency in your Spring Boot application:
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-spring-boot-starter</artifactId>
<version>1.4.0</version>
</dependency>Or follow the instructions for Gradle in Section 2.3.
That starter itself depends on the Neo4j Java Driver. The driver is managed by Spring Boot since 2.4, and you can enjoy configuration support directly through Spring Boot. For Spring Boot versions prior to Spring Boot 2.4, please have a look at version 0.0.13 of this library.
Neo4j-Migrations will automatically look for migrations in classpath:neo4j/migrations and will fail if this location does not exist.
It does not scan by default for Java-based migrations.
Here’s an example on how to configure the driver and the migrations:
spring.neo4j.authentication.username=neo4j
spring.neo4j.authentication.password=secret
spring.neo4j.uri=bolt://localhost:7687
# Add configuration for your migrations, for example, additional packages to scan
org.neo4j.migrations.packages-to-scan=your.changesets, another.changeset
# Or disable the check if the location exists
org.neo4j.migrations.check-location=falseHave a look at Section 4.4.2 for all supported properties.
4.4.1. Usage with @DataNeo4jTest
If you want to use your migrations together with @DataNeo4jTest which is provided with Spring Boot out of the box,
you have to manually import our autoconfiguration like this:
import ac.simons.neo4j.migrations.springframework.boot.autoconfigure.MigrationsAutoConfiguration;
import org.junit.jupiter.api.Test;
import org.neo4j.driver.Driver;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.ImportAutoConfiguration;
import org.springframework.boot.test.autoconfigure.data.neo4j.DataNeo4jTest;
import org.springframework.test.context.DynamicPropertyRegistry;
import org.springframework.test.context.DynamicPropertySource;
import org.testcontainers.containers.Neo4jContainer;
import org.testcontainers.junit.jupiter.Container;
import org.testcontainers.junit.jupiter.Testcontainers;
import org.testcontainers.utility.TestcontainersConfiguration;
@Testcontainers(disabledWithoutDocker = true)
@DataNeo4jTest (1)
@ImportAutoConfiguration(MigrationsAutoConfiguration.class) (2)
public class UsingDataNeo4jTest {
@Container
private static Neo4jContainer<?> neo4j = new Neo4jContainer<>("neo4j:4.2")
.withReuse(TestcontainersConfiguration.getInstance().environmentSupportsReuse()); (3)
@DynamicPropertySource
static void neo4jProperties(DynamicPropertyRegistry registry) { (4)
registry.add("spring.neo4j.uri", neo4j::getBoltUrl);
registry.add("spring.neo4j.authentication.username", () -> "neo4j");
registry.add("spring.neo4j.authentication.password", neo4j::getAdminPassword);
}
@Test
void yourTest(@Autowired Driver driver) {
// Whatever is tested
}
}| 1 | Use the dedicated Neo4j test slice |
| 2 | Import this auto-configuration (which is not part of Spring Boot) |
| 3 | Bring up a container to test against |
| 4 | Use DynamicPropertySource for configuring the test resources dynamically |
4.4.2. Available configuration properties
The following configuration properties in the org.neo4j.migrations namespace are supported:
| Name | Type | Default | Description |
|---|---|---|---|
|
|
|
Whether to check that migration scripts location exists. |
|
|
|
The database that should be migrated (Neo4j EE 4.0+ only). Leave {@literal null} for using the default database. |
|
|
|
The database that should be used for storing information about migrations (Neo4j EE 4.0+ only). Leave {@literal null} for using the default database. |
|
|
|
An alternative user to impersonate during migration. Might have higher privileges than the user connected, which will be dropped again after migration. Requires Neo4j EE 4.4+. Leave {@literal null} for using the connected user. |
|
|
|
Whether to enable Neo4j-Migrations or not. |
|
|
|
Encoding of Cypher migrations. |
|
|
|
Username recorded as property {@literal by} on the MIGRATED_TO relationship. |
|
|
|
Locations of migrations scripts. |
|
|
|
List of packages to scan for Java migrations. |
|
|
|
The transaction mode in use (Defaults to "per migration", meaning one script is run in one transaction). |
|
|
|
Validating helps you verify that the migrations applied to the database match the ones available locally and is on by default. |
|
|
|
Automatically convert Windows line-endings (CRLF) to LF when reading resource based migrations, pretty much what the same Git option does during checkin. |
Migrations can be disabled by setting org.neo4j.migrations.enabled to false.
|
4.5. Quarkus
We provide an extension with automatic configuration for Quarkus. Declare the following dependency in your Quarkus application:
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-quarkus</artifactId>
<version>1.4.0</version>
</dependency>That extension itself depends on the Neo4j Java Driver and the corresponding Quarkus extension Quarkus-Neo4j and requires at least Quarkus 2.6. You don’t need to declare those dependencies, they are already transitive dependencies of this extension.
Neo4j-Migrations will automatically look for migrations in classpath:neo4j/migrations and will fail if this location does not exist.
It does not scan by default for Java-based migrations.
Here’s an example on how to configure the driver and the migrations:
quarkus.neo4j.uri=bolt://localhost:7687
quarkus.neo4j.authentication.username=neo4j
quarkus.neo4j.authentication.password=secret
org.neo4j.migrations.packages-to-scan=foo.barIf you disable Neo4j-Migrations via org.neo4j.migrations.enabled we won’t apply Migrations at startup but the Migrations object
will still be in the context to be used.
All other properties available for the Spring-Boot-Starter are available for the Quarkus extension, too.
Their namespace is the same: org.neo4j.migrations.
|
4.5.1. Build-time vs runtime config
org.neo4j.migrations.packages-to-scan and org.neo4j.migrations.locations-to-scan are build-time configuration options
and cannot be changed during runtime. This allows for optimized images to be created: All migrations that are part of the
classpath (both scripts and class based migrations) are discovered during image build-time already and are included in
the image themselves (this applies to both native and JVM images).
While scripts in file system locations (all locations starting with file://) are still discovered during runtime and thus
allows for scripts being added without recreating the application image, the location cannot be dynamically changed. If you
need a dynamic, file:// based location, use org.neo4j.migrations.external-locations. This property is changeable during
runtime and allows for one image being used in different deployments pointing to different external locations with scripts
outside the classpath
An alternative approach to that is using the CLI in a sidecar container, pointing to the dynamic location and keep applying database migrations outside the application itself.
4.5.2. Dev Services integration
Neo4j-Migrations will appear as a tile in the Quarkus Dev UI under http://localhost:8080/q/dev/. It provides a list of migrations which can be used to clean the database or apply all migrations. The latter is handy when migrate at start is disabled or in case there are callbacks that might reset or recreate testdata.
4.6. Maven-Plugin
You can trigger Neo4j-Migrations from your build a Maven-Plugin. Please refer to the dedicated Maven-Plugin page for a detailed list of all goals and configuration option as well as the default lifecycle mapping of the plugin.
4.6.1. Configuration
Most of the time you will configure the following properties for the plugin:
<plugin>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-maven-plugin</artifactId>
<version>1.4.0</version>
<executions>
<execution>
<configuration>
<user>neo4j</user>
<password>secret</password>
<address>bolt://localhost:${it-database-port}</address>
<verbose>true</verbose>
</configuration>
</execution>
</executions>
</plugin>All goals provide those properties.
By default, the plugin will look in neo4j/migrations for Cypher-based migrations.
You can change that via locationsToScan inside the configuration element like this:
<locationsToScan>
<locationToScan>file://${project.build.outputDirectory}/custom/path</locationToScan>
</locationsToScan>Add multiple locationToScan elements for multiple locations to scan.
4.6.2. Goals
All goals as described in Section 4.1 are supported.
-
clean, see Section 4.1.1
-
info, see Section 4.1.2
-
migrate, see Section 4.1.3
-
clean, see Section 4.1.4
The above list links to the corresponding Maven-Plugin page, please check those goals out for further details.
Appendix
Glossary
- Pending migration
-
See Resolved migration.
- Resolved migration
-
A migration that has been resolved in the classpath or the filesystem which has not been yet applied.
- Schema database
-
A database inside a Neo4j enterprise instance or cluster that stores the schema information from Neo4j-Migrations.
- Target database
-
A database inside a Neo4j enterprise instance or cluster that is refactored by Neo4j-Migrations.