© Copyright 2020-2022 the original author or authors.
This is the Neo4j-Migrations manual version 3.2.0.
1. Introduction
1.1. About
Neo4j-Migrations are a set of tools to make your schema migrations as easy as possible. They provide a uniform way for applications, the command line and build tools alike to track, manage and apply changes to your database, in short: to refactor your database. The project is inspired to a large extent by FlywayDB, which is an awesome tool for migration of relational databases. Most things evolve around Cypher scripts, however the Core API of Neo4j-Migrations allows defining Java classes as migrations as well.
Neo4j-Migrations builds directly on top of the official Neo4j Java driver, supports Neo4j 3.5, Neo4j 4.1 to 4.4 and Neo4j 5, including enterprise features such as multidatabase support and impersonation.
The only dependencies are said driver and ClassGraph, the latter being used to find migrations on the classpath.
The history of migrations applied is stored as a subgraph in your database.
1.2. Compatibility
Neo4j-Migrations is tested only against Neo4j, the world’s leading Graph database. Neo4j-Migrations requires a 5.2+ version of Neo4j Java Driver. Therefore, Neo4j-Migrations works with Neo4j 3.5, 4.1 - 4.4, 5 and of course, Neo4j-Aura. It also can be used with an embedded instance, as long as the embedded instances provides the Bolt-Connector, too. The tooling may or may not work with other databases using the Bolt protocol. We don’t provide any support for those.
The Core API and the JVM based version of the CLI module of Neo4j-Migrations requires at least Java 17 or higher since version 2.0. Neo4j-Migrations can safely be used on both the class- and module-path. Native binaries are provided for 64bit versions of macOS, Linux and Windows. The native binaries don’t require a JVM to be installed.
For a version compatible with JDK 8, check the 1.x releases. We still do maintain the latest minor, including support for older versions of Spring Boot (prio to Spring Boot 3). These are also the versions you should be using against Neo4j 4.0.
The older releases of Neo4j-Migrations are compiled with JDK 17 while targeting JDK 8.
The Core API is provided as a Multi-Release-Jar in the older releases, providing a module-info.java for JDK 11 and higher, making it a good citizen on the Java module path as well.
1.3. Versions
Neo4j-Migrations 1.0.0 has been considered stable and was first released in November 2021. Since then, we ensure semantic versioning. This means in cases where you use the Java API directly, you can be sure that patch releases won’t break your application, and you can always upgrade.
1.4. Modules
Neo4j-Migrations comes in different flavors:
- Core
-
The core module, providing an API to run both Cypher script and Java-based migrations. The API includes builders for configuration. Of course, Neo4j-Migrations works on the module path, and it also has an explicit, correct module definition with a clear API boundary. In addition, we do make use of sealed interfaces for things that are meant to be implemented only by us.
JavaDoc and Project info
- CLI
-
A command line tool that supports every interaction that the core module provides. Native binaries are available for Linux, macOS and Windows. If you want to use Java-based migrations in the CLI, you must use the JVM distribution. This is an ideal tool to be put into CI/CD not based on Maven or Gradle.
- Spring-Boot-Starter
-
Provides all configuration options via the well-known Spring-Boot-Properties mechanism and turns them into a fully configured Migrations instance that will be applied on application start. Scripts will be searched sane default location.
JavaDoc and Project info
- Quarkus
-
An extension for Quarkus, providing full integration of all configuration option via Quarkus' configuration. Creates a startup observer that applies all resolved migrations at startup.
JavaDoc and Project info
- Maven-Plugin
-
A Maven-plugin that hooks clean, apply and verify operations into the appropriate Maven lifecycles. Use this to apply migrations during your build.
1.5. Changelog
We provide a full changelog on GitHub: Neo4j-Migrations. Our commits follow conventional commits. The releases are created and published via JReleaser.
1.6. History
The original idea of Neo4j-Migrations was conceived when working on integrating Spring Data Neo4j (back then SDN/RX) into JHipster. We needed some Nodes, constraints and relationship to be present in the Neo4j database for JHipster to do it’s magic but back then there was no lightweight (in terms of dependencies) tool that did work well with Neo4j 4.0 (the first Graph database providing reactive data access out of the box). Neo4j-Migrations filled that gap in early 2020 and has grown ever since.
2. Download
2.1. CLI
2.1.1. SDKMAN!
Neo4j-Migrations is on SDKMAN! and can be installed via
sdk install neo4jmigrationson Windows, Linux and macOS x86_64. Arm binaries are not yet available.
2.1.2. For homebrew users on macOS
brew install michael-simons/homebrew-neo4j-migrations/neo4j-migrationsAutocompletion is automatically installed and available for bash and zsh when you configured Homebrew accordingly.
2.1.3. Linux
As download from our release page:
curl -LO https://github.com/michael-simons/neo4j-migrations/releases/download/3.2.0/neo4j-migrations-3.2.0-linux-x86_64.zip2.1.4. Windows
As download from our release page:
curl -LO https://github.com/michael-simons/neo4j-migrations/releases/download/3.2.0/neo4j-migrations-3.2.0-windows-x86_64.zip2.1.5. Architecture independent
In addition to the above native binaries we still offer a JVM, architecture independent version of Neo4j-Migrations-CLI.
Only the JVM version does support custom, Java-based migrations as shown via the argument --package, the natively compiled versions do not.
Get this version here:
curl -LO https://github.com/michael-simons/neo4j-migrations/releases/download/3.2.0/neo4j-migrations-3.2.0.zip|
The architecture independent version can be used via Neo4js official JBang catalog:
With JBang installed, run jbang neo4j-migrations@neo4j --help for printing our usage information.
The catalog offers a couple of other scripts as well, check them out with jbang catalog list neo4j.
|
2.2. Core API
The easiest way to get the Core API is to use a build- and dependency-management tool like Maven or Gradle. Here are the coordinates:
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations</artifactId>
<version>3.2.0</version>
</dependency>Or in case you fancy Gradle:
dependencies {
implementation 'eu.michael-simons.neo4j:neo4j-migrations:3.2.0'
}2.3. Spring-Boot-Starter
Use your dependency management to include the Spring-Boot-Starter.
The starter automatically triggers the dependency to the Neo4j-Java-Driver, which than can be configured via properties in the spring.neo4j.* namespace.
This starter here has a custom namespace, please refer to for more information.
<dependencies>
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-spring-boot-starter</artifactId>
<version>3.2.0</version>
</dependency>
</dependencies>Or in case you fancy Gradle:
dependencies {
implementation 'eu.michael-simons.neo4j:neo4j-migrations-spring-boot-starter:3.2.0'
}2.4. Quarkus
Use your dependency management to include the Quarkus extension.
This extension automatically triggers the dependency to the Neo4j extension containing the Neo4j-Java-Driver.
The latter can be configured via properties in the quarkus.neo4j.* namespace.
The namespace for this extension is also org.neo4j.migrations.*.
<dependencies>
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-quarkus</artifactId>
<version>3.2.0</version>
</dependency>
</dependencies>2.5. Maven-Plugin
Include the Maven-Plugin like this in your build and configure it according to the usage section:
<plugins>
<plugin>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-maven-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<user>neo4j</user>
<password>secret</password>
<address>bolt://localhost:${it-database-port}</address>
<verbose>true</verbose>
</configuration>
<executions>
<execution>
<id>migrate</id>
<goals>
<goal>migrate</goal>
</goals>
</execution>
<execution>
<id>default-validate</id>
<goals>
<goal>validate</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>3. Concepts
This chapter deals with various concepts that are applicable for all modules offered. Especially checkout the page regarding naming conventions, for all Cypher and Java-based migrations and callbacks.
3.1. Connectivity
Neo4j-Migrations solely uses the Neo4j Java Driver.
Most of the time you pass a pre-configured driver object to our API.
The Spring-Boot-Plugin depends on the driver-instance provided by Spring-Boot which can be configured via properties in the spring.neo4j.* space.
The CLI and Maven-Plugin offer parameters to define the URL, username and password alike.
All of this mean that we can keep this chapter short and basically defer to the driver’s documentation:
The Neo4j Java Driver Manual v4.4.
For ease of use, here are the most common forms of URLs the driver might take.
The URLS all have this format: <NEO4J_PROTOCOL>://<HOST>:<PORT>.
The Neo4j-Protocol might be one of the following:
| URI scheme | Routing | Description |
|---|---|---|
|
Yes |
Unsecured |
|
Yes |
Secured with full certificate |
|
Yes |
Secured with self-signed certificate |
|
No |
Unsecured |
|
No |
Secured with full certificate |
|
No |
Secured with self-signed certificate |
You don’t have to care much more about the Driver API than knowing how to create an instance:
import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Config;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
class HowToCreateADriverInstance {
public static void main(String... args) {
Driver driver = GraphDatabase.driver(
"neo4j://your.database.io",
AuthTokens.basic("neo4j", "secret"),
Config.defaultConfig()
);
}
}This instance needs to be passed than to the Neo4j-Migrations Core API in case you aren’t using one of our integrations. Mostly everything else than can be done via Cypher scripts alone. If you need more control about what happens in a migration, have a look at our Java-based migration support.
3.2. Locations
You need to store migrations somewhere. Essentially, Neo4j-Migrations offers three categories:
-
class- or module-path based packages
-
classpath based locations
-
file based locations
The former does support Java (and Kotlin) classes, the two latter only supports Cypher (and XML) based scripts, for obvious reasons: Neo4j-Migrations won’t pick up external Java files and compile them for you.
Packages are configured through packagesToScan in MigrationConfig. A corresponding property is available in all framework integrations and in the CLI.
Locations for resources must be configured through locationsToScan. Again, a corresponding property is available in all framework integrations and in the CLI. Additionally, the Quarkus integration offers externalLocations. Why? Because locationsToScan will be treated by Quarkus as build-time properties and be resolved during built-time, becoming part of the Jar-file or native image. Hence, you wouldn’t be able to change them later. externalLocations will stay flexible, the semantics however are the same.
3.2.1. classpath: or file: protocol?
Neo4j-Migrations differentiates for the locationsToScan option between the classpath: and the file: protocol with the following syntax and semantics:
a/b/c-
Implicitly assuming
classpath:, treating the valuea/b/cas the packagea.b.c. /a/b/c-
Implicitly assuming
classpath:, treating the valuea/b/cas the packagea.b.c, the leading forward-slash is superfluous and will be stripped. classpath:a/b/crespectivelyclasspath:/a/b/c-
Same as the above, but explicitly enabling classpath scanning in the given package.
./whatever/../a/b/c-
Implicitly assuming
file:, indicated by the leading dot (.), which has the same semantics as in a filesystem. Neo4j-Migrations will resolve the given relative path against the current working directory and look there for a directory structure ofa/b/c. ../migrations/a/b/c-
Implicitly assuming
file:, indicated by the leading dots (..), which have the same semantics as in a filesystem. Neo4j-Migrations will resolve the given relative path against the current working directory and look in its parent directory for a directory structure ofmigrations/a/b/c. - Using the
file:uri scheme -
This one is a bit tricky, and you might want to read up about it here. Neo4j-Migrations is strict about the number of forward slashes here: A valid file URI must begin with either
file:/path(no hostname),file:///path(empty hostname), orfile://hostname/path. Neo4j-Migrations will strip away any hostname, relative paths are not allowed within thefile:uri scheme and will be stripped away.
Note: Scanning the root package is not supported, as it might become slow and sometimes dangerous, too. In the end, you would not want to bring in a dependency that might contain a Cypher resource that fit the naming conventions of Neo4j-Migrations and truncate your database, would you?
Any configured file-system location that does not exist or isn’t a directory will be logged on WARNING level.
3.3. Migrations
Migrations are all operations or refactorings you apply to a database. These operations might be creating, changing, or dropping indexes and constraints or altering data. Sometimes you might even want to create users or databases.
Cypher (.cypher), Catalog-based (.xml) and class based (i.e. .java or .kt) based migrations require a certain naming
convention to be recognized:
V1_2_3__Add_last_name_index.(cypher|xml|java)-
Prefix
Vfor "Versioned migration" orRfor "Repeatable migration" -
Version with optional underscores separating as many parts as you like
-
Separator:
__(two underscores) -
Required description: Underscores or spaces might be used to separate words
-
Suffix: Depending on the given type.
Exceptions are made for callbacks (see naming conventions) and some extensions supported by Neo4j-Migrations.
3.3.1. Cypher-based
Cypher-based migrations can be mostly anything you can write down as Cypher statement.
A Cypher-based migration can contain one or more statements with multiple lines separated by a ; followed by a new line.
By default, all statements in one script will be executed in a single transaction.
Here’s an example:
CREATE (agent:`007`) RETURN agent;
UNWIND RANGE(1,6) AS i
WITH i CREATE (n:OtherAgents {idx: '00' + i})
RETURN n
;This script contains two different statements.
Neo4j-Migrations will by default look in classpath:neo4j/migrations for all *.cypher files matching the name described in
Section 3.6. You can change (or add to this default) with the Core API or the appropriate properties in
Spring-Boot-Starter or the Maven-Plugin like this:
MigrationsConfig configLookingAtDifferentPlaces = MigrationsConfig.builder()
.withLocationsToScan(
"classpath:my/awesome/migrations", (1)
"file:/path/to/migration" (2)
).build();| 1 | Look at a different place on the classpath |
| 2 | Look additional at the given filesystem path |
Switching database inside Cypher scripts
With the command :USE
The command :USE has the same meaning as in Neo4j-Browser or Cypher-Shell: All following commands will be applied in the given database.
The transaction mode will be applied as configured per database and will "restart" when you switch the database again.
This is the preferred way of doing things like this:
:USECREATE database foo IF NOT EXISTS WAIT;
:use foo;
CREATE (n:InFoo {foo: 'bar'});
:use neo4j;
CREATE (n:InNeo4j);With the Cypher keyword USE
It is of course possible to use the Cypher keyword USE <graph> (See USE) inside your scripts.
There are a couple of things to remember, though:
-
It can get tricky if you combine it in creative ways with the options for schema- and target-databases Neo4j-Migrations offer itself
-
If you have more than one statement per script (which is completely not a problem) and one of them should use
USEyou must configure Neo4j-Migrations to useTransactionMode#PER_STATEMENT(see Section 3.9, meaning to run each statement of a script in a separate transaction. This is slightly more error-prone, as it will most likely leave your database in an inconsistent state if one statement fails, since everything before has already been committed.
3.3.2. Based on a catalog
Migrations can be used to define a local catalog in an iterative fashion. Each migration discovered will contribute to a catalog
known in the context of a Migration instance.
Catalog based migrations are written in XML and can contain one <catalog /> item per migration and many <operation /> items
per migration.
The simplest way of defining a catalog based migrations looks like this:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<create>
<constraint name="unique_isbn" type="unique">
<label>Book</label>
<properties>
<property>isbn</property>
</properties>
</constraint>
</create>
</migration>Here a unique constraint is defined for the property isbn of all nodes labelled Book. This constraint is known only locally
and does not contribute to the contextual catalog.
This can also be rewritten such as this:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<catalog>
<constraints>
<constraint name="unique_isbn" type="unique">
<label>Book</label>
<properties>
<property>isbn</property>
</properties>
</constraint>
</constraints>
</catalog>
<create item="unique_isbn"/>
</migration>The constraint can be reused later, too:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<drop item="unique_isbn"/>
</migration>Indexes are supported, too:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<create>
<index name="node_index_name">
<label>Person</label>
<properties>
<property>surname</property>
</properties>
</index>
</create>
</migration>
The XML schema supports types for indexes as well: FULLTEXT and TEXT. The former being the well known
Lucene backed indexes, the latter the new TEXT index introduced in Neo4j.
|
To learn more about the scheme, have a look at the XML schema explained and also make sure you follow the concepts about catalogs as well as the catalog examples.
Last but not least, Neo4j-Migrations offers several built-in refactorings, modelled after APOC Refactor but without requiring APOC to be installed inside the database or cluster.
The example given in the APOC docs above can be identically modelled with the following catalog item:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<refactor type="rename.label">
<parameters>
<parameter name="from">Engineer</parameter>
<parameter name="to">DevRel</parameter>
<parameter name="customQuery"><![CDATA[
MATCH (person:Engineer)
WHERE person.name IN ["Mark", "Jennifer", "Michael"]
RETURN person
]]></parameter>
</parameters>
</refactor>
</migration>It will rename the label Engineer on all nodes matching the custom query to DevRel.
All supported refactorings are described in Refactorings.
What’s the advantage of using XML instead of a Cypher-based migration for this purpose? The syntax for defining constraints and indexes has been changed considerably over the last decade of Neo4j versions and many variants that used to be possible in Neo4j 3.5 have been deprecated for a while and will vanish in Neo4j 5.0.
With a neutral representation of constraints and indexes, we can translate these items into the syntax that fits your target database. In addition, we also can do idempotent operations on older databases that don’t actually have them.
Furthermore, some structured form is necessary for creating a representation of concepts like refactorings.
What’s the advantage of using Catalog-based migrations for the purpose of creating constraints and indexes for specific versions of Neo4j compared to Cypher-based migrations with preconditions? When using preconditions it is up to you to take care of newer versions of Neo4j as they come available as well as making sure you get the syntax right. Using a Catalog-based migration frees you from this duty. Preconditions have been available earlier than the concept of a catalog and can be used for many purposes (i.e. making sure actual data exists). In contrast to that, Catalog-based migrations have a very strong focus on actual schema items.
However, Catalog-based migrations offer support for preconditions too. They can be added as XML processing instructions anywhere in the document and look like this:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<?assert that edition is enterprise ?>
<?assume q' RETURN true?>
</migration>They can appear anywhere in the document, but we recommend putting them into the root element.
While both elements - constraint and index - do support a child element named options, these are not
rendered or used yet.
|
3.3.3. Java-based
Neo4j-Migrations provides the interface ac.simons.neo4j.migrations.core.JavaBasedMigration for you to implement.
Based on that interface you can do much more than just migrate things via adding or changing data:
You can refactor everything in your database in a programmatic way.
One possible migration looks like this:
package some.migrations;
import ac.simons.neo4j.migrations.core.JavaBasedMigration;
import ac.simons.neo4j.migrations.core.MigrationContext;
import org.neo4j.driver.Driver;
import org.neo4j.driver.Session;
public class V001__MyFirstMigration implements JavaBasedMigration {
@Override
public void apply(MigrationContext context) {
try (Session session = context.getSession()) { (1)
// Steps necessary for a migration
}
}
}| 1 | The MigrationContext provides both getSession() or getSessionConfig() to be used in combination with getDriver().
The latter is helpful when you want to have access to a reactive or asynchronous session.
It is important that you use the convenience method getSession() or create a session with the provided config as only
those guarantee that your database session will be connected to the configured target database with the configured user.
In addition, our context will take care of managing Neo4j causal cluster bookmarks.
However, if you feel like it is necessary to switch to a different database, you can use the driver instance any way you want.
The transaction handling inside Java-based migrations is completely up to you. |
You don’t have to annotate your Java-based migrations in any way. Neo4j-Migrations will find them on the classpath as is. The same naming requirements that apply to Cypher scripts apply to Java-based migrations as well, see Section 3.6.
|
There are some restrictions when it comes to run Neo4j-Migrations on GraalVM native image:
You might or might not be able to convince the runtime to find implementations of an interface in native image.
You must at least explicitly include those classes in the native image unless used otherwise as well.
The CLI will outright refuse to scan for Java-based migrations in its native form (when using the --package option).
It does support them only in JVM mode.
|
While you can theoretically extend the public base interface Migration too, we don’t recommend it.
In fact, on JDK 17 we forbid it.
Please use only JavaBasedMigration as the base interface for your programmatic migrations.
3.4. Callbacks
Callbacks are part of a refactoring or a chain of migration that lives outside the chain of things.
As such these callbacks can be used to make sure certain data, constructs or other preconditions are available or fulfilled before anything else happens.
They also come in handy during integration tests.
You might want to have your migrations as part of the main source tree of your application and
at the same time have in your tests source tree the same folder with a bunch of callbacks that
create test data for example in an afterMigrate event.
Callbacks are not considered immutable after they have been invoked and their invocation is not stored in the history graph. This gives you a hook to add some more volatile things to your refactoring.
The beforeFirstUse callback is especially handy in cases in which you want to create the target database before migrations
are applied: It will always be invoked inside the home database of the connected user, so at this point, the target database
does not need to exist yet.
Be aware that for this to work you must specify both target and schema database: The schema database must exist
and cannot be created with a beforeFirstUse callback. This due to the fact that migrations will always be run inside
lock represented by a couple of Nodes.
An appropriate CLI call would look like this: neo4j-migrations --schema-database neo4j --database canBeCreatedWithCallback apply
A corresponding callback would contain: CREATE DATABASE canBeCreatedWithCallback IF NOT EXISTS;
|
3.4.1. Lifecycle phases
The following phases are supported:
- beforeFirstUse
-
The only phase that only runs once for any given instance of Neo4j-Migrations. It will run before any other operations are called, when the first connection is opened. Callbacks in this phase will always be invoked in the schema database and not the target database, so they won’t require the target database to be present. Also, no user impersonation will be performed. This can be used to create the target database before any migrations or validations are run.
- beforeMigrate
-
Before migrating a database.
- afterMigrate
-
After migrating a database, independent of outcome.
- beforeClean
-
Before cleaning a database.
- afterClean
-
After cleaning a database, independent of outcome.
- beforeValidate
-
Before validating a database.
- afterValidate
-
After validating a database, independent of outcome.
- beforeInfo
-
Before getting information about the target database.
- afterInfo
-
After getting information about the target database.
3.5. Using a catalog of items
Neo4j is schema free or a database with little schema. There are labels for nodes, types for relationships and both can have properties. Hence, property graph. But there’s no "hard" schema determining that all nodes have all the same properties with the same type.
However, there are concepts to force the existence of properties on entities: Constraints. Constraints can also enforce uniqueness and keys; they go hand in hand with indexes. Constraints and indexes are what we refer to in Neo4j-Migrations as schema.
|
Why the heck XML? While XML has been badmouthed for a while now, it has a couple of advantages over JSON and YAML,
especially in terms of schema: There are many options to validate a given document, Document Type Definition (DTD)
and XML Schema being two of them. Neo4j-Migrations opted for the latter, it is documented in the appendix.
Most of your tooling should be able to load this and validate any migration for you and guide you to what is possible
and what not.
Our benefit lies in the fact that XML support comes directly with the JVM, and we don’t need to introduce any additional dependencies to parse and validate content. |
A catalog is also used to represent predefined or built-in refactorings, such as renaming all occurrences of types or labels.
3.5.1. What is a catalog?
Inside Neo4j-Migrations the concept of a catalog has been introduced. A catalog holds the same type of entities as a schema and migrations can pick up elements from the catalog to define the final schema.
Items can reside multiple times inside the catalog, identified by their id and the version of the migration in which they have been defined. This is so that a drop operation for example can refer to the last version of an entity applied to the schema and not to the latest, in which properties or options might have change.
Refactorings exists as a general concept in a catalog, they don’t need to be defined, but just declared as an operation to be executed.
How is a catalog defined?
The catalog comes in two flavors, the remote and the local catalog. The remote catalog - or in other words the catalog defined by the databases' schema - is the easier one to understand: It is a read-only view on all items contained in the database schema that Neo4j-Migrations supports, such as constraints and indexes. It can be retrieved on demand any time.
The local catalog is a bit more complex: It is built in an iterative way when discovering migrations. Catalog-based migrations
are read in versioning order. Items in their <catalog /> definition are required to have a unique id (name) per migration.
All items are added in a versioned manner to the local catalog. If an item named a is defined in both version n and n+x,
it will be accessible in the catalog in both variants. Thus, Neo4j-Migrations can for example support dropping of unnamed
items and recreating them in a new fashion. The approach of a versioned, local catalog also allows executing advanced operations
like verify: The verification of the remote catalog against the local catalog triggered in migration n+1 can refer to
the local catalog in version n (the default) to assert the ground for all following operations, or for the current version
to make sure everything exists in a given point in time without executing further operations.
Last but not least: Sometimes it is required to start fresh in a given migration. For this purpose the catalog element supports
an additional attribute reset. Setting this to true in any given migration will cause the catalog to be reset in this version.
Resetting means either being replaced with an empty catalog (<catalog reset="true" />) or replaced with the actual content.
3.5.2. Operations working with a catalog
Operations available to catalog based migrations are
create-
Create an item
drop-
Drop an item
verify-
Verify the locally defined catalog against the remote schema
apply-
Drop all supported types from the remote schema and create all elements of the local catalog.
refactor-
Execute one of several predefined refactorings
While create and drop work on single item, verify and apply work on the whole, known catalog in a defined version range.
A word on naming: Neo4j-Migrations requires unique names of catalog items across the catalog. In contrast to the
Neo4j database itself, using the name wurstsalat for both a constraint and an index is prohibited. Recommended
names in this case would be wurstsalat_exists and wurstsalat_index.
|
Both create and drop operations are idempotent by default.
This behaviour can be changed using ifNotExists and ifExists attributes with a value of false.
Be aware that idempotent does not mean "force", especially in the create case. If you want to update / replace an existing
constraint, and you are unsure if it does exist or not, use
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<drop item="a" ifExists="true" />
<create item="a" />
</migration>The drop operation will ensure that the constraint goes away, and the create operation will safely build a new one.
Verification (or assertions)
verify asserts that all items in the catalog are present in an equivalent or identical form in the database. This is a useful
step inside a migration to make sure things are "as you expect" before applying further migrations. Thus, it can only be
used before running any create, drop or apply commands.
The catalog items that are subject to the verification are by default made up from all prior versions to the migration
in which the verify appears. As an example, inside migration V2.1 a verify appears. All catalog items from versions
1.0 upto 2.0 will take part of the assertion. Items defined in 2.1 with the same name won’t be asserted, so that you can
assert a given state and then redefine parts of it for example.
This behavior can be changed by using the attribute latest, setting it to true on the element (<verify latest="true" />).
This will take the catalog as defined in this version.
Applying the whole catalog
apply on the other hands drops all items in the current physical schema and creates all items in state of the catalog
at the current version of migration. From the same example as above, everything from 1.0 upto and including 2.1 will be
included, definitions will be identified by their name respectively id.
The apply operation loads all supported item types from the database, drops them and then creates all items of
the local catalog. This is a potentially destructive operation as it might drop items you have no replacement for.
Also be aware that neo4j-migrations will never drop the constraints needed for the locking node to function proper (Basically, none of the constraints defined for the label __Neo4jMigrationsLock).
|
apply can’t be used together with drop or create in the same migration.
Executing refactorings
refactor is used to run parameterized predefined refactorings. The refactor element can be used after the verify operation and before, after or in between drop or create operations. It will be executed in the order in which it was defined. It cannot be used together with apply.
Have a look at the general catalog example or at the appendix for some concrete examples of executing predefined refactorings.
3.5.3. Create a catalog from the actual database schema
The API provides getDatabaseCatalog and getLocalCatalog methods.
The former reads all supported items in the Neo4j schema and creates a catalog view on them, the latter provides access
to the catalog defined by all migrations.
Those methods are used by the CLI to provide the ability to dump the whole database schema as a catalog definition in our own XML format or as Cypher script targeting a specific Neo4j version.
Last but not least, there’s public API ac.simons.neo4j.migrations.core.catalog.CatalogDiff.between that can be used to
diff two catalogs and evaluate whether they are identical, equivalent or different to each other.
Refactorings cannot be derived from an existing database.
3.6. Naming conventions
3.6.1. Cypher-based resources
All Cypher-based resources (especially migration and callback scripts) require .cypher as extension.
The Core API, the Spring-Boot-Starter and the Maven-Plugin will by default search for such Cypher scripts in classpath:neo4j/migrations.
The CLI has no default search-location.
Migration scripts
A Cypher script based migration must have a name following the given pattern to be recognized:
V1_2_3__Add_last_name_index.cypher-
Prefix
Vfor "Versioned migration" orRfor "Repeatable migration" -
Version with optional underscores separating as many parts as you like
-
Separator:
__(two underscores) -
Required description: Underscores or spaces might be used to separate words
-
Suffix:
.cypher
This applies to both Cypher scripts outside an application (in the file system) and inside an application (as resources).
| Cypher-based migrations scripts are considered to be immutable once applied. We compute their checksums and record it inside the schema database. If you change a Cypher-based migration after it has been applied, any further application will fail. By marking a migration as repeatable you indicate that it is safe to repeat it whenever its checksum changes. |
Callback scripts
A Cypher script is recognized as a callback for a given lifecycle if it matches the following pattern:
nameOfTheLifecyclePhase.cypher
nameOfTheLifecyclePhase__optional_description.cyphernameOfTheLifecyclePhase must match exactly (case-sensitive) the name of one of the supported lifecycle phases (see Section 3.4.1),
followed by an optional description and the suffix .cypher, separated from the name of the phase by two underscores (__).
The description is used to order different callback scripts for the same lifecycle phase.
If you use more than one script in the same lifecycle phase without a description, the order is undefined.
Callback scripts are not considered to be immutable and can change between execution.
If you use DDL statements such as CREATE USER or CREATE DATABASE in them make sure you look for an IF NOT EXITS
option in your desired clause so that these statements become idempotent.
|
3.6.2. Catalog-based migrations
Catalog-based migrations (See Section 3.5) are XML files based on the migration.xsd scheme. As such they require
the extension .xml and otherwise follow the same naming conventions as Cypher-based resources.
3.6.3. Java-based migrations
For Java (or actually anything that can be compiled to a valid Java class) based migrations, the same naming conventions apply as for
Cypher-based scripts apart from the extension.
To stick with the above example, V1_2_3__Add_last_name_index.cypher becomes V1_2_3__Add_last_name_index as simple class name,
or in source form, V1_2_3__Add_last_name_index.java.
Our recommendation is to use something like this:
public class V1_2_3__AddLastNameIndex implements JavaBasedMigration {
@Override
public void apply(MigrationContext context) {
// Your thing
}
@Override
public String getSource() {
return "Add last name index"; (1)
}
}| 1 | Defaults to the simple class name being added to the history chain. |
3.7. Chain of applied migrations
All migrations applied to a target database are stored in the schema database. The target and the schema database can be the same database. If you are an enterprise customer managing different databases for different tenants that are however used for the same application, it makes absolutely sense to use a separate schema database that stores all data related to Neo4j-Migrations.
The subgraph will look like this:
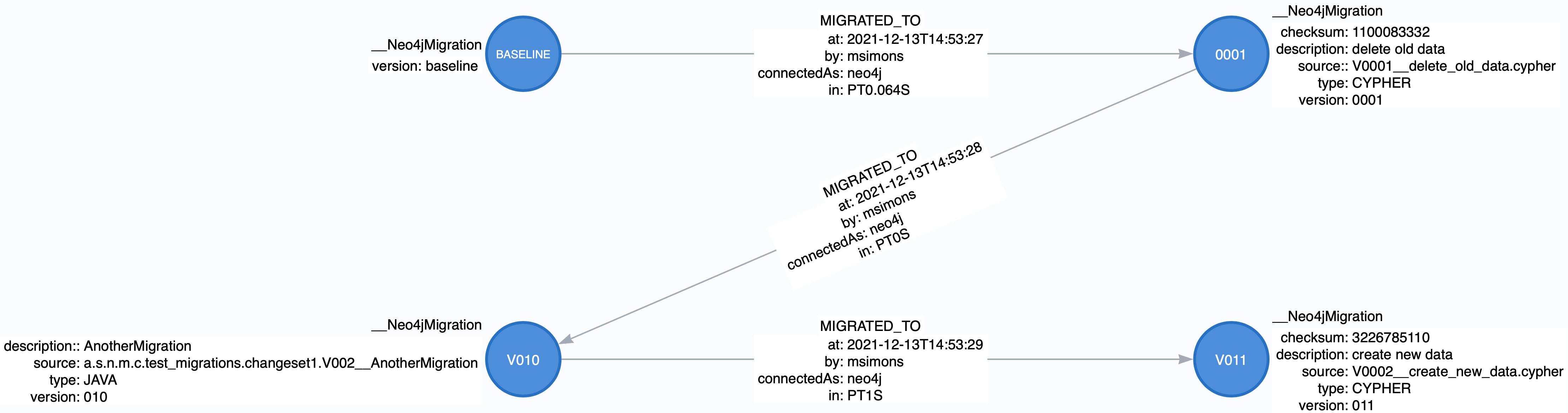
In case you use a schema database for any database with a different name than the default (which is neo4j) the nodes
labelled __Neo4jMigration will have an additional property name migrationTarget which contains the target graph.
3.8. Separate schema databases
Since version 1.1.0 you can use a different database for storing information about migrations.
You need to run a Neo4j 4+ Enterprise Edition.
The command line argument and the property, respectively, is schema-database throughout the configuration.
The name given must be a valid Neo4j database name (See Administration and configuration).
The database must exist and the user must have write access to it.
Valid scenarios are:
-
Using a schema database for one other database
-
Using a schema database for maintaining multiple migrations of different databases
-
Using pairs of schema databases and target databases
Neo4j-Migrations will create subgraphs in the schema database identifiable by a migrationTarget-property in the __Neo4jMigration-nodes.
Neo4j-Migrations will not record a migrationTarget for the default database (usually neo4j),
so that this feature doesn’t break compatibility with schemas created before 1.1.0.
| It is usually a good idea to separate management data (like in this case the chain of applied migrations) from you own data, whether the latter is created or changed by refactorings itself or by an application). So we recommend to use separated databases when you’re on enterprise edition. |
3.9. Transactions
All operations that are managed by Neo4j-Migrations directly, except catalog-based migrations, are executed inside transactional functions. This is essentially a scope around one or more statements which will be retried on certain conditions (for example, on losing connectivity inside a cluster setup).
You can configure if all statements of one Cypher-based migration go into one transactional function or if each statement goes into its own transactional scope:
MigrationsConfig configPerMigration = MigrationsConfig.builder()
.withTransactionMode(MigrationsConfig.TransactionMode.PER_MIGRATION)
.build();
// OR
MigrationsConfig configPerStatement = MigrationsConfig.builder()
.withTransactionMode(MigrationsConfig.TransactionMode.PER_STATEMENT)
.build();Per Migration is the default, as we think it’s safer: Either the whole migration is applied (or failed) or none. But there are certain scenarios that require a transaction per statement, for example most DDL operations such as creating databases might not be run together with DML operations in the same transaction.
| Catalog-based migrations - that is creation of indexes and constraints through the dedicated Neo4j-Migrations API - are always executed inside auto-commit transactions, as the underlying connectivity has some deficiencies that don’t allow retries or continuing using a transaction in some failure conditions that might happen during the creation of schema items. |
3.10. Preconditions
Our Cypher based migrations support a set of simple assertions and assumptions as preconditions prior to execution.
Preconditions can be added as a single-line Cypher comment to a script. Multiple preconditions in one script must all be
met (logically chained with AND).
- Assertions
-
Preconditions starting with
// assertare hard requirements. If they cannot be satisfied by the target database, Neo4j-Migrations will abort. - Assumptions
-
Preconditions starting with
// assumeare soft requirements. If they cannot be satisfied, the corresponding script will be skipped and not be part of any chain.
| If you think that preconditions might change (for example when asking for a specific version): Make sure you have alternative scripts with the same filename available, both having preconditions meeting the matching cases. We will treat them as alternatives and make sure that a changed checksum is not treated as an error. For example this would happen if you suddenly one migration has its precondition met which it didn’t before and therefore changing the chain of applied migrations. |
3.10.1. Require a certain edition
The Neo4j edition can be required with either
// assume that edition is enterpriseor
// assume that edition is community.3.10.2. Require a certain version
The Neo4j version can be required with
// assume that version is 4.3Multiple versions can be enumerated after the is separated by a ,.
Version ranges can be required with lt (lower than) or ge (greater than or equals), for example:
// assume that version is ge 4.0Both assumptions combined makes it safe to use version assumptions (see the warning above). We recommend using one refactoring for the minimum version you support and one for all higher that support the feature you want. For example: Your minimum supported database version is 4.3 and you want to create an existential constraint. You want to have 2 migrations:
// assert that edition is enterprise
// assume that version is 4.3
CREATE CONSTRAINT isbn_exists IF NOT EXISTS ON (book:Library) ASSERT exists(book.isbn);And the different one for 4.4 or higher:
// assert that edition is enterprise
// assume that version is ge 4.4
CREATE CONSTRAINT isbn_exists IF NOT EXISTS FOR (book:Library) REQUIRE book.isbn IS NOT NULL;The former will only applied to the 4.3, the latter to 4.4 or higher. If your user upgrades their database at some point, Neo4j-Migrations will recognize that it used an older, compatible script with it and wont fail, even though the new script has a different checksum.
3.10.3. Preconditions based on Cypher queries
You can require a precondition based on a query that must return a single, boolean value via
// assume q' RETURN trueThe above case will of course always be satisfied.
Here’s a complete example:
// assert that edition is enterprise
// assert that version is 4.4
// assume q' MATCH (book:Library) RETURN count(book) = 0
CREATE CONSTRAINT isbn_exists IF NOT EXISTS FOR (book:Library) REQUIRE book.isbn IS NOT NULL;This refactoring will only execute on Neo4j 4.4 enterprise (due to the requirements of existence constraints and the 4.4 syntax being used)
and will be ignored when there are already nodes labeled Library.
3.10.4. Why only preconditions for scripts?
Since we offer full programmatic access to migrations together with the context that has information about the Neo4j version, edition and access to both target and schema database, it would be duplicate work if we take the decision away from you. You are completely free inside a programmatic refactoring not to do anything in a given context. The migration will be dutifully recorded nevertheless.
3.10.5. Upgrading older database
Given that your application needs to support multiple versions of Neo4j, including versions that didn’t exist when you created your application originally and you might have invalid Cypher now in potentially already applied migrations you can do the following
-
Create sub-folders in your migration locations or configure additional locations
-
Duplicate the migrations that contain Cypher that is problematic in newer Neo4j versions
-
Keep the names of the migrations identical and distribute them accordingly in these folders
-
Add a precondition matching only older versions of Neo4j to one and keep the rest unaltered
-
Adapt the other one containing only "good" syntax and add a precondition for the newer Neo4j version
Thus, you support the following scenarios:
-
On older database versions against which your application already ran, nothing will change; the migration with the fixed syntax will be skipped
-
Same for a clean slate on older database versions
-
On the newer database version, only the fixed syntax migration will be applied.
3.11. Repairing migrations
Sometimes things will break, either on purpose or by accident. When a migration chain is broken, it will fail to validate. This can happen for various reasons:
-
You change a Cypher script file after it has been applied and its application has been successfully recorded
-
You migrate your database as part of your application startup and not with a CI process and used different versions of your application with a different set of migration scripts and classes
-
You delete individual script files or classes
In all those cases, the chain of applied migrations won’t validate with the current set of migrations discovered. Apart from using the clean operation which would remove the whole chain from your database inevitably leading to all migrations to be re-applied, you have several options to repair your database:
-
Delete the offending migrations - those are all for which no script or class can be resolved anymore - individually from the database with the
deleteoperation. -
Use the
repairoperation
The repair operation behaves as follows:
-
Check all the checksums (pairwise by migration version) and fix the recorded chain if necessary
-
Check for missing local migrations and delete the missing ones in the database
-
Check for inserted local migrations and create new chain entries with current time stamp
Especially the second step has consequences: If there aren’t any local migrations all recorded migrations would be deleted. As misconfigurations can happen (for example during a typo in a path), the repair operation will abort if it doesn’t find any local migrations. If you want to clean up the database, use the clean operation explicitly.
The repair operation will never apply any migration. Everything it does is fixing the chain of recorded application. Basically it pretends that everything that has been discovered locally has been applied to the database so that you can start on a clean slate.
|
As the repair command won’t apply migrations itself, it will stop after the last applied migration. An example: You have 3 local migrations, v1*, v3 and v4. The chain recorded however is (v1) → (v2) → (v3). This means, v1 has changed, it’s checksum doesn’t match, v2 has been deleted and v4 is new. The repair command will now fix the checksum, delete v2 and then stop, so that the chain now is this: (v1*) → (v3). v4 can be applied now with the standard apply operation.
3.11.1. Example
Given the following scenario:
neo4j-migrations -uneo4j -pverysecret --location=file:$MIGRATIONS info
neo4j@localhost:7687 (Neo4j/5.4.0 Community Edition)
Database: neo4j
+---------+----------------------------+---------+-------------------------------+---------------+----------------+---------+---------------------------------------------+
| Version | Description | Type | Installed on | by | Execution time | State | Source |
+---------+----------------------------+---------+-------------------------------+---------------+----------------+---------+---------------------------------------------+
| 007 | BondTheNameIsBond | CYPHER | 2023-03-06T10:55:07.971Z[UTC] | msimons/neo4j | PT0.041S | APPLIED | V007__BondTheNameIsBond.cypher |
| 007.1 | BondTheNameIsBondNew | CYPHER | 2023-03-06T10:55:08.059Z[UTC] | msimons/neo4j | PT0.018S | APPLIED | V007_1__BondTheNameIsBondNew.cypher |
| 007.1.1 | BondTheNameIsBondNewNew | CYPHER | 2023-03-06T10:55:08.144Z[UTC] | msimons/neo4j | PT0.034S | APPLIED | V007_1_1__BondTheNameIsBondNewNew.cypher |
| 008 | Create constraints | CATALOG | 2023-03-06T10:55:08.186Z[UTC] | msimons/neo4j | PT0.02S | APPLIED | V008__Create_constraints.xml |
| 021 | Die halbe Wahrheit | CYPHER | 2023-03-06T10:55:08.253Z[UTC] | msimons/neo4j | PT0.035S | APPLIED | V021__Die halbe Wahrheit.cypher |
| 021.1 | Die halbe Wahrheit neu | CYPHER | 2023-03-06T10:55:08.304Z[UTC] | msimons/neo4j | PT0.011S | APPLIED | V021.1__Die halbe Wahrheit neu.cypher |
| 021.1.1 | Die halbe Wahrheit neu neu | CYPHER | 2023-03-06T10:55:08.320Z[UTC] | msimons/neo4j | PT0.005S | APPLIED | V021.1.1__Die halbe Wahrheit neu neu.cypher |
| 4711 | MirFallenKeineNamenEin | CYPHER | 2023-03-06T10:55:08.346Z[UTC] | msimons/neo4j | PT0.016S | APPLIED | V4711__MirFallenKeineNamenEin.cypher |
| 5000 | WithCommentAtEnd | CYPHER | 2023-03-06T10:55:08.372Z[UTC] | msimons/neo4j | PT0.015S | APPLIED | V5000__WithCommentAtEnd.cypher |
| 5002 | AMigration | CATALOG | 2023-03-06T10:55:08.382Z[UTC] | msimons/neo4j | PT0S | APPLIED | V5002__AMigration.xml |
+---------+----------------------------+---------+-------------------------------+---------------+----------------+---------+---------------------------------------------+And the following local changes:
rm $MIGRATIONS/moreStuff/V007__BondTheNameIsBond.cypher
echo "CREATE (n:IWasHere)" >> $MIGRATIONS/V021__Die\ halbe\ Wahrheit.cypher
echo "CREATE (n:IWasHere)" >> $MIGRATIONS/V5001__ANewMigration.cypher
echo "CREATE (n:IWasHere)" >> $MIGRATIONS/V5003__AnotherNewMigration.cypherNow, trying to re-apply all migrations will fail:
neo4j-migrations -uneo4j -pverysecret --location=file:$MIGRATIONS apply
[2023-03-06T11:59:23.780439000] Invoked beforeMigrate callback.
[2023-03-06T11:59:23.807065000] Invoked afterMigrate callback.
Unexpected migration at index 0: 007.1 ("BondTheNameIsBondNew").The info command will fail with the same error. The chain can be repaired like this:
neo4j-migrations -uneo4j -pverysecret --location=file:$MIGRATIONS repair
The migration chain in the default database has been repaired: 1 nodes and 3 relationships have been deleted, 1 nodes and 3 relationships have been recreated.The result looks like this
neo4j-migrations -uneo4j -pverysecret --location=file:$MIGRATIONS info
neo4j@localhost:7687 (Neo4j/5.4.0 Community Edition)
Database: neo4j
+---------+----------------------------+---------+-------------------------------+---------------+----------------+---------+---------------------------------------------+
| Version | Description | Type | Installed on | by | Execution time | State | Source |
+---------+----------------------------+---------+-------------------------------+---------------+----------------+---------+---------------------------------------------+
| 007.1 | BondTheNameIsBondNew | CYPHER | 2023-03-06T10:55:07.971Z[UTC] | msimons/neo4j | PT0.041S | APPLIED | V007_1__BondTheNameIsBondNew.cypher |
| 007.1.1 | BondTheNameIsBondNewNew | CYPHER | 2023-03-06T10:55:08.144Z[UTC] | msimons/neo4j | PT0.034S | APPLIED | V007_1_1__BondTheNameIsBondNewNew.cypher |
| 008 | Create constraints | CATALOG | 2023-03-06T10:55:08.186Z[UTC] | msimons/neo4j | PT0.02S | APPLIED | V008__Create_constraints.xml |
| 021 | Die halbe Wahrheit | CYPHER | 2023-03-06T10:55:08.253Z[UTC] | msimons/neo4j | PT0.035S | APPLIED | V021__Die halbe Wahrheit.cypher |
| 021.1 | Die halbe Wahrheit neu | CYPHER | 2023-03-06T10:55:08.304Z[UTC] | msimons/neo4j | PT0.011S | APPLIED | V021.1__Die halbe Wahrheit neu.cypher |
| 021.1.1 | Die halbe Wahrheit neu neu | CYPHER | 2023-03-06T10:55:08.320Z[UTC] | msimons/neo4j | PT0.005S | APPLIED | V021.1.1__Die halbe Wahrheit neu neu.cypher |
| 4711 | MirFallenKeineNamenEin | CYPHER | 2023-03-06T10:55:08.346Z[UTC] | msimons/neo4j | PT0.016S | APPLIED | V4711__MirFallenKeineNamenEin.cypher |
| 5000 | WithCommentAtEnd | CYPHER | 2023-03-06T10:55:08.372Z[UTC] | msimons/neo4j | PT0.015S | APPLIED | V5000__WithCommentAtEnd.cypher |
| 5001 | ANewMigration | CYPHER | 2023-03-06T11:00:39.311Z[UTC] | msimons/neo4j | PT0S | APPLIED | V5001__ANewMigration.cypher |
| 5002 | AMigration | CATALOG | 2023-03-06T10:55:08.382Z[UTC] | msimons/neo4j | PT0S | APPLIED | V5002__AMigration.xml |
| 5003 | AnotherNewMigration | CYPHER | | | | PENDING | V5003__AnotherNewMigration.cypher |
+---------+----------------------------+---------+-------------------------------+---------------+----------------+---------+---------------------------------------------+007 has been deleted, checksum of 021 has been fixed, 5001 has been inserted and 5003 is still pending.
4. Usage
4.1. Common operations
4.1.1. Clean
clean applies by default to the schema database.
It will remove Neo4j-Migrations related nodes and relationships.
If there is no schema database selected, it works on the optional target database.
If this isn’t configured either, the users home database will be used.
The clean operation will search for
-
Migration chains (those are the nodes containing information about the applied migrations)
-
Any log from this Neo4j-Migrations
-
Any constraints created by Neo4j-Migrations
and will delete and drop them in that order. This is a destructive operation, so make sure not to apply it to your production database without thinking at least twice. It cannot be undone via Neo4j-Migrations.
The operation takes in a boolean parameter.
When set to false, only the migration chain for the currently configured target database will be deleted.
When set to true, all objects created by Neo4j-Migrations will be deleted.
4.1.2. Delete
The delete operation comes in handy when the migrations fail to validate. This might be the case when you accidentally or on purpose deleted script files or refactored Java based migrations away. The delete operation takes in the unique version or the name of a Cypher script file or a Java class, looks for a migration in the migration chain fitting that description and deletes it. If it was the last migration in the chain, the previous one will be the new last, otherwise the previous migration will point to the next one.
Using the delete operation is one way of repairing broken migration chains.
4.1.3. Info
The info operations returns information about the context, the database, all applied and all pending applications.
4.1.4. Migrate / apply
The migrate command (or its underlying method apply in the Migrations Core API) does exactly that:
It applies all locally resolved migrations to the target database and stores the chain of applied migrations in the schema database.
It returns the last applied version.
That operation does not allow migrations out-of-order by default.
That means if you add version 2 after you already migrated to 5, it will fail with an appropriate error.
You can spot these cases beforehand by validating your chain of migrations (see below).
If you absolutely must however, you can use withOutOfOrderAllowed on the config object or the corresponding property in either the Spring Boot starter or the Quarkus extension.
Setting this to true will integrate out-of-order migrations into the chain.
By default, all migrations will be applied.
However, you can configure a target version to stop at.
The target version will always be an inclusive stop.
This is especially important for repeatable migrations: If the target is repeatable and has changed since the last application, it will be applied again.
The target version must be an exact version number as given with the file- or classname (such as V1_2_3, R010, V100 or whatever scheme you use), specifying the description again is not necessary (See ref:concepts.adoc#concepts_naming-conventions[naming conventions]).
Migrations does check whether the target version can be resolved and will abort if there is no such version, either in pending or applied state).
You can use V010? (with a question mark) to skip this check.
Migrations will then apply every version that is sorted below that version.
Additionally, three special values are supported as well (These names are case-insensitive):
current-
Designates the current version of the schema.
latest-
The latest version of the schema, as defined by the migration with the highest version.
next-
The next version of the schema, as defined by the first pending migration.
4.1.5. Repair
The repair operation is an emergency operation for all those cases in which
-
Local migrations have been changed (incidentally or on purpose) so that their checksums now mismatch
-
Local migrations are deleted
-
Applying migrations failed for whatever reasons
so that the chain of applied migrations does not fit with the discovered migrations anymore. This operation will fix checksums, automatically delete locally missing migrations from the chain and insert placeholder migrations into the chain if necessary. It does stop at the end of the chain (all migrations discovered after that can be applied with apply in the regular way), does not apply migrations itself after the fact and will fail hard in case no local migrations can be found (if this is the case, use clean to remove all recorded migrations.)
4.1.6. Validate
The validate operations resolves all local migrations and checks whether all have applied in the same order and in the
same version to the configured database.
A target database will validate as valid when all migrations have been applied in the right order and invalid in any cases
where migrations are missing, have not been applied, applied in a different order or with a different checksum.
The validation result provides an additional operation needsRepair().
In case the result is invalid you might check if it needs repair.
If not, you can just call the apply operation to turn the database into a valid state.
4.2. CLI
Please choose the version of Neo4j-Migrations-CLI fitting your operating system or target system as described in download. In the following we assume you downloaded and unzipped the architecture independent version. For that version to work, you need to have JDK 17 or higher installed:
java -version
curl -LO https://github.com/michael-simons/neo4j-migrations/releases/download/3.2.0/neo4j-migrations-3.2.0.zip
unzip neo4j-migrations-3.2.0.zip
cd neo4j-migrations-3.2.0
./bin/neo4j-migrations -VThose commands should first print out your Java version, then download, extract and run Neo4j-Migrations-CLI to give you its version.
| If you only deal with Cypher-based migrations and don’t have the need for any programmatic migrations, we provide a native binary for your platform, make sure to choose that. Its startup time is faster, and you don’t need to have a JVM installed. |
4.2.1. All options and arguments
The CLI comes with a build-in help, accessible via neo4j-migrations -h or neo4j-migrations --help:
./bin/neo4j-migrations --help
Usage: neo4j-migrations [-hvV] [--autocrlf] [--validate-on-migrate] -p
[=<password>] [-p[=<password>]]... [-a=<address>]
[-d=<database>] [--impersonate=<impersonatedUser>]
[--schema-database=<schemaDatabase>]
[--transaction-mode=<transactionMode>] [-u=<user>]
[--location=<locationsToScan>]...
[--package=<packagesToScan>]... [COMMAND]
Migrates Neo4j databases.
-a, --address=<address> The address this migration should connect to. The
driver supports bolt, bolt+routing or neo4j as
schemes.
--autocrlf Automatically convert Windows line-endings (CRLF)
to LF when reading resource based migrations,
pretty much what the same Git option does during
checkin.
-d, --database=<database> The database that should be migrated (Neo4j EE 4.0
+).
-h, --help Show this help message and exit.
--impersonate=<impersonatedUser>
The name of a user to impersonate during migration
(Neo4j EE 4.4+).
--location=<locationsToScan>
Location to scan. Repeat for multiple locations.
-p, --password[=<password>]
The password of the user connecting to the database.
--package=<packagesToScan>
Package to scan. Repeat for multiple packages.
--schema-database=<schemaDatabase>
The database that should be used for storing
information about migrations (Neo4j EE 4.0+).
--transaction-mode=<transactionMode>
The transaction mode to use.
-u, --username=<user> The login of the user connecting to the database.
-v Log the configuration and a couple of other things.
-V, --version Print version information and exit.
--validate-on-migrate Validating helps you verify that the migrations
applied to the database match the ones available
locally and is on by default.
Commands:
clean Removes Neo4j-Migration specific data from the selected
schema database.
delete Deletes a migration from the chain of applied migrations.
help Display help information about the specified command.
info Retrieves all applied and pending information, prints them
and exits.
init Creates a migration project inside the current folder.
migrate, apply Retrieves all pending migrations, verify and applies them.
repair Compares locally discovered migrations with the remote chain
and repairs the remote chain if necessary; no migrations
will be applied during this process, only the migration
chain will be manipulated. This command requires at least
one local migration.
run Resolves the specified migrations and applies them. Does not
record any metadata.
show-catalog Gets the local or remote catalog and prints it to standard
out in the given format.
validate Resolves all local migrations and validates the state of the
configured database with them.If no values are given to either location or packages we check for a directory structure of neo4j/migrations inside
the current working directory and use that as a default for location if such a structure exists.
The info command takes a mode option as an optional argument:
Usage: neo4j-migrations info [mode=<mode>]
Retrieves all applied and pending informations, prints them and exits.
mode=<mode> Controls how the information should be computed. Valid
options are COMPARE, LOCAL, REMOTE with COMPARE being the
default. COMPARE will always compare locally discovered
and remotely applied migrations, while the other options
just check what's there.
This means that we by default compare what has been discovered locally with what has been applied in the database:
We check for missing or superfluous migrations and also compare checksums.
At times, you might want to have just a quick look at what is in the database, without configuring a local filesystem.
Use mode=remote in that case: We just look at what is in the database and assume everything is applied.
Use mode=local to print out what has been discovered locally with the current settings and would be applied to an empty database.
neo4j-migrations looks in the current working directory for a properties file called .migration.properties which
can contain all supported options. Use such a file to avoid repeating long command lines all the time.
Use neo4j-migrations init to create a file with the default values. Any options passed to neo4j-migrations before
the init command will also be store.
|
4.2.2. Output
Direct information coming from the CLI itself will always go to standard out. Information coming from core migrations will be locked with a timestamp on standard error. This allows for controlled redirection of different information.
4.2.3. Safe passwords in CI/CD usage
There are 4 ways to specify the password:
-
interactive: Use
--passwordwithout arguments and your shell will prompt you with a hidden prompt. -
direct: Use
--password not-so-secret. The password will be visible in the shell history and in the process monitor. -
Via environment variable: Define an environment variable like
MY_PASSWORDand use--password:env MY_PASSWORD. Note that the parameter is the name of the variable, not the resolved value. -
Via a file: Create a file in a safe space and add your password in a single line in that file and use
--password:file path/to/your/passwordFile. The password will be read from this file.
The last two options are a safe choice in scripts or in a CI/CD environment.
4.2.4. Well-known Neo4j environment variables
Neo4j AuraDB provides .env files when creating new instances that look like this:
# Wait 60 seconds before connecting using these details, or login to https://console.neo4j.io to validate the Aura Instance is available
NEO4J_URI=neo4j+s://xxxx.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=somepassword
AURA_INSTANCENAME=Instance01Neo4j-Migrations will recognize those environment variables when present. If you didn’t specify a value for username, password or address and those variables are present and not empty, Neo4j-Migrations will use them.
Above file can be directly used in a command like this (on a *Nix-system):
set -o allexport (1)
(source ~/Downloads/credentials-xxx.env; neo4j-migrations info)
set +o allexport| 1 | Might not be needed in your shell |
4.2.5. Enable autocompletion for Neo4j-Migrations in your shell
Neo4j-Migrations can generate a shell script providing autocompletion for its options in Bash, zsh and others. Here’s how to use it:
./bin/neo4j-migrations generate-completion > neo4j-migrations_completion.shThe generated script neo4j-migrations_completion.sh can than be run via . neo4j-migrations_completion.sh or permanently installed by
sourcing it in your ~/.bashrc or ~/.zshrc.
If you want to have autocompletion for Neo4j-Migrations just in your current shell use the following command
source <(./bin/neo4j-migrations generate-completion)| Autocompletion for macOS is automatically installed when you use Homebrew. |
4.2.6. Full example
Here’s an example that looks for migrations in a Java package, its subpackages and in a filesystem location for Cypher-based migrations.
In this example we have exported the directory with our Java-based migrations like this: export CLASSPATH_PREFIX=~/Projects/neo4j-migrations/neo4j-migrations-core/target/test-classes/.
Please adapt accordingly to your project and / or needs.
The example uses the info command to tell you which migrations have been applied and which not:
./bin/neo4j-migrations -uneo4j -psecret \
--location file:$HOME/Desktop/foo \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset1 \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset2 \
info
neo4j@localhost:7687 (Neo4j/4.4.0)
Database: neo4j
+---------+-----------------------------+--------+--------------+----+----------------+---------+--------------------------------------------------------------+
| Version | Description | Type | Installed on | by | Execution time | State | Source |
+---------+-----------------------------+--------+--------------+----+----------------+---------+--------------------------------------------------------------+
| 001 | FirstMigration | JAVA | | | | PENDING | a.s.n.m.c.t.changeset1.V001__FirstMigration |
| 002 | AnotherMigration | JAVA | | | | PENDING | a.s.n.m.c.t.changeset1.V002__AnotherMigration |
| 023 | NichtsIstWieEsScheint | JAVA | | | | PENDING | a.s.n.m.c.t.changeset2.V023__NichtsIstWieEsScheint |
| 023.1 | NichtsIstWieEsScheintNeu | JAVA | | | | PENDING | a.s.n.m.c.t.changeset2.V023_1__NichtsIstWieEsScheintNeu |
| 023.1.1 | NichtsIstWieEsScheintNeuNeu | JAVA | | | | PENDING | a.s.n.m.c.t.changeset2.V023_1_1__NichtsIstWieEsScheintNeuNeu |
| 030 | Something based on a script | CYPHER | | | | PENDING | V030__Something_based_on_a_script.cypher |
| 042 | The truth | CYPHER | | | | PENDING | V042__The_truth.cypher |
+---------+-----------------------------+--------+--------------+----+----------------+---------+--------------------------------------------------------------+You can repeat both --package and --location parameter for fine-grained control.
Use migrate to apply migrations:
./bin/neo4j-migrations -uneo4j -psecret \
--location file:$HOME/Desktop/foo \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset1 \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset2 \
migrate
[2022-05-31T11:25:29.894372000] Applied migration 001 ("FirstMigration").
[2022-05-31T11:25:29.985192000] Applied migration 002 ("AnotherMigration").
[2022-05-31T11:25:30.001006000] Applied migration 023 ("NichtsIstWieEsScheint").
[2022-05-31T11:25:30.016117000] Applied migration 023.1 ("NichtsIstWieEsScheintNeu").
[2022-05-31T11:25:30.032421000] Applied migration 023.1.1 ("NichtsIstWieEsScheintNeuNeu").
[2022-05-31T11:25:30.056182000] Applied migration 030 ("Something based on a script").
[2022-05-31T11:25:30.077719000] Applied migration 042 ("The truth").
Database migrated to version 042.If we go back to the info example above and grab all migrations again, we find the following result:
./bin/neo4j-migrations -uneo4j -psecret \
--location file:$HOME/Desktop/foo \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset1 \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset2 \
info
Database: Neo4j/4.0.0@localhost:7687
+---------+-----------------------------+--------+-------------------------------+---------------+----------------+---------+--------------------------------------------------------------+
| Version | Description | Type | Installed on | by | Execution time | State | Source |
+---------+-----------------------------+--------+-------------------------------+---------------+----------------+---------+--------------------------------------------------------------+
| 001 | FirstMigration | JAVA | 2021-12-14T12:16:43.577Z[UTC] | msimons/neo4j | PT0S | APPLIED | a.s.n.m.c.t.changeset1.V001__FirstMigration |
| 002 | AnotherMigration | JAVA | 2021-12-14T12:16:43.876Z[UTC] | msimons/neo4j | PT0.032S | APPLIED | a.s.n.m.c.t.changeset1.V002__AnotherMigration |
| 023 | NichtsIstWieEsScheint | JAVA | 2021-12-14T12:16:43.993Z[UTC] | msimons/neo4j | PT0S | APPLIED | a.s.n.m.c.t.changeset2.V023__NichtsIstWieEsScheint |
| 023.1 | NichtsIstWieEsScheintNeu | JAVA | 2021-12-14T12:16:44.014Z[UTC] | msimons/neo4j | PT0S | APPLIED | a.s.n.m.c.t.changeset2.V023_1__NichtsIstWieEsScheintNeu |
| 023.1.1 | NichtsIstWieEsScheintNeuNeu | JAVA | 2021-12-14T12:16:44.035Z[UTC] | msimons/neo4j | PT0S | APPLIED | a.s.n.m.c.t.changeset2.V023_1_1__NichtsIstWieEsScheintNeuNeu |
| 030 | Something based on a script | CYPHER | 2021-12-14T12:16:44.093Z[UTC] | msimons/neo4j | PT0.033S | APPLIED | V030__Something_based_on_a_script.cypher |
| 042 | The truth | CYPHER | 2021-12-14T12:16:44.127Z[UTC] | msimons/neo4j | PT0.011S | APPLIED | V042__The truth.cypher |
+---------+-----------------------------+--------+-------------------------------+---------------+----------------+---------+--------------------------------------------------------------+Another migrate - this time with all packages - gives us the following output and result:
./bin/neo4j-migrations -uneo4j -psecret \
--location file:$HOME/Desktop/foo \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset1 \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset2 \
migrate
[2022-05-31T11:26:23.054169000] Skipping already applied migration 001 ("FirstMigration")
[2022-05-31T11:26:23.058779000] Skipping already applied migration 002 ("AnotherMigration")
[2022-05-31T11:26:23.059185000] Skipping already applied migration 023 ("NichtsIstWieEsScheint")
[2022-05-31T11:26:23.059504000] Skipping already applied migration 023.1 ("NichtsIstWieEsScheintNeu")
[2022-05-31T11:26:23.059793000] Skipping already applied migration 023.1.1 ("NichtsIstWieEsScheintNeuNeu")
[2022-05-31T11:26:23.060068000] Skipping already applied migration 030 ("Something based on a script")
[2022-05-31T11:26:23.060329000] Skipping already applied migration 042 ("The truth")
Database migrated to version 042.The database will be now in a valid state:
./bin/neo4j-migrations -uneo4j -psecret \
--location file:$HOME/Desktop/foo \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset1 \
--package ac.simons.neo4j.migrations.core.test_migrations.changeset2 \
validate
All resolved migrations have been applied to the default database.4.2.7. Using the CLI as a script runner
The CLI can be used as a simple runner for migrations scripts as well. The only necessity is that all scripts have well-defined names according to the format described here:
./bin/neo4j-migrations -uneo4j -psecret \
run \
--migration file:`pwd`/../../../neo4j-migrations-core/src/test/resources/manual_resources/V000__Create_schema.cypher \
--migration file:`pwd`/../../../neo4j-migrations-core/src/test/resources/manual_resources/V000__Create_graph.cypher \
--migration file:`pwd`/../../../neo4j-migrations-core/src/test/resources/manual_resources/V000__Refactor_graph.xml
[2022-09-27T17:24:11.589274000] Applied 000 ("Create graph")
[2022-09-27T17:24:11.860457000] Applied 000 ("Refactor graph")
Applied 2 migration(s).| You can specify as many resources as you want. They will be applied in order. No checks will be done whether they have already been applied or not and no metadata will be recored. |
4.2.8. A template for Java-based migrations
As stated above, this will work only with the JVM distribution. Follow those steps:
curl -LO https://github.com/michael-simons/neo4j-migrations/releases/download/3.2.0/neo4j-migrations-3.2.0.zip
unzip neo4j-migrations-3.2.0.zip
cd neo4j-migrations-3.2.0
mkdir -p my-migrations/some/migrations
cat <<EOT >> my-migrations/some/migrations/V001__MyFirstMigration.java
package some.migrations;
import ac.simons.neo4j.migrations.core.JavaBasedMigration;
import ac.simons.neo4j.migrations.core.MigrationContext;
import org.neo4j.driver.Driver;
import org.neo4j.driver.Session;
public class V001__MyFirstMigration implements JavaBasedMigration {
@Override
public void apply(MigrationContext context) {
try (Session session = context.getSession()) {
}
}
}
EOT
javac -cp "lib/*" my-migrations/some/migrations/*
CLASSPATH_PREFIX=my-migrations ./bin/neo4j-migrations -v -uneo4j -psecret --package some.migrations info| We do add this here for completeness, but we do think that Java-based migrations makes most sense from inside your application, regardless whether it’s a Spring Boot, Quarkus or just a plain Java application. The CLI should be seen primarily as a script runner. |
4.3. Core API
We publish the Java-API-Docs here: Neo4j Migrations (Core) 3.2.0 API. Follow the instructions for your favorite dependency management tool to get hold of the core API as described in download.
The classes you will be working with are ac.simons.neo4j.migrations.core.MigrationsConfig and its related builder and
ac.simons.neo4j.migrations.core.Migrations and maybe ac.simons.neo4j.migrations.core.JavaBasedMigration in case you
want to do programmatic refactorings.
4.3.1. Configuration and usage
Configuration is basically made up of two parts:
Creating a driver instance that points to your database or cluster as described in the Connectivity section and an instance of MigrationsConfig.
An instance of MigrationsConfig is created via a fluent-builder API.
Putting everything together looks like this:
Migrations based on a configuration object and the Java driverMigrations migrations = new Migrations(
MigrationsConfig.builder()
.withPackagesToScan("some.migrations")
.withLocationsToScan(
"classpath:my/awesome/migrations",
"file:/path/to/migration"
)
.build(),
GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "secret"))
);
migrations.apply(); (1)| 1 | Applies this migration object and migrates the database |
In case anything goes wrong the API will throw a ac.simons.neo4j.migrations.core.MigrationsException.
Of course your migrations will be recorded as a chain of applied migrations (as nodes with the label __Neo4jMigration) as well when you use the API directly.
The following operations are available:
- clean
-
Cleans the selected schema database from every metadata created by this tool
- delete
-
Removes a single migration from the chain of applied migrations
- info
-
Returns information about the context, the database, all applied and all pending applications
- apply
-
Applies all discovered migrations
- repair
-
Repairs the chain of applied migrations without applying pending or reapplying local migrations
- run
-
Runs a single script without recording it as a migration in the chain of applied migrations
- validate
-
Validates the database against the resolved migrations
All operations are available in the CLI and Maven-Plugin, except for the delete and run operations, which are only in the Core-API and the CLI.
The corresponding starter for Spring Boot respectively the Quarkus extension will automatically run apply.
apply comes in a couple of overloads:
-
It will apply all discovered migrations when called without arguments or with a single boolean argument i
-
It will try to resolve URLS to supported migrations and apply them as is, without writing metadata when called with one or more URLs as argument. This method can also be ce called through the CLI (via the
runcommand). -
It will apply all refactorings in order when called with one or more instances of
Refactoring. This method is only available in the Core API. Please read more about it here: Applying refactorings programmatically.
4.3.2. Running on the Java module-path
Neo4j-Migrations can be used on the Java module path. Make sure you require them in your module and export packages with Java-based migrations in case you’re using the latter. Resources on the classpath should be picked up automatically:
module my.module {
requires ac.simons.neo4j.migrations.core;
exports my.module.java_based_migrations; (1)
}| 1 | Only needed when you actually have those |
4.4. Spring-Boot-Starter
We provide a starter with automatic configuration for Spring Boot. Declare the following dependency in your Spring Boot application:
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-spring-boot-starter</artifactId>
<version>3.2.0</version>
</dependency>Or follow the instructions for Gradle in download.
That starter itself depends on the Neo4j Java Driver. The driver is managed by Spring Boot since 2.4, and you can enjoy configuration support directly through Spring Boot. For Spring Boot versions prior to Spring Boot 2.4, please have a look at version 0.0.13 of this library.
Neo4j-Migrations will automatically look for migrations in classpath:neo4j/migrations and will fail if this location does not exist.
It does not scan by default for Java-based migrations itself.
It will however discover all Java-based migrations that are annotated with @Component, @Service or other stereotypes and all beans that made it otherwise into the application context.
Such a Java-based migrations is free to use anything that is injectable itself, such as Spring Data Neo4j repositories.
Here’s an example on how to configure the driver and the migrations:
spring.neo4j.authentication.username=neo4j
spring.neo4j.authentication.password=secret
spring.neo4j.uri=bolt://localhost:7687
# Add configuration for your migrations, for example, additional packages to scan
org.neo4j.migrations.packages-to-scan=your.changesets, another.changeset
# Or disable the check if the location exists
org.neo4j.migrations.check-location=falseHave a look at Section 4.4.2 for all supported properties.
The starter will log some details about the product version and the database connected to. This can be disabled by setting the logger ac.simons.neo4j.migrations.core.Migrations.Startup to a level higher than INFO.
|
4.4.1. Usage with @DataNeo4jTest
If you want to use your migrations together with @DataNeo4jTest which is provided with Spring Boot out of the box,
you have to manually import our autoconfiguration like this:
import ac.simons.neo4j.migrations.springframework.boot.autoconfigure.MigrationsAutoConfiguration;
import org.junit.jupiter.api.Test;
import org.neo4j.driver.Driver;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.ImportAutoConfiguration;
import org.springframework.boot.test.autoconfigure.data.neo4j.DataNeo4jTest;
import org.springframework.test.context.DynamicPropertyRegistry;
import org.springframework.test.context.DynamicPropertySource;
import org.testcontainers.neo4j.Neo4jContainer;
import org.testcontainers.junit.jupiter.Container;
import org.testcontainers.junit.jupiter.Testcontainers;
import org.testcontainers.utility.TestcontainersConfiguration;
@Testcontainers(disabledWithoutDocker = true)
@DataNeo4jTest (1)
@ImportAutoConfiguration(MigrationsAutoConfiguration.class) (2)
public class UsingDataNeo4jTest {
@Container
private static Neo4jContainer neo4j = new Neo4jContainer("neo4j:4.4")
.withReuse(TestcontainersConfiguration.getInstance().environmentSupportsReuse()); (3)
@DynamicPropertySource
static void neo4jProperties(DynamicPropertyRegistry registry) { (4)
registry.add("spring.neo4j.uri", neo4j::getBoltUrl);
registry.add("spring.neo4j.authentication.username", () -> "neo4j");
registry.add("spring.neo4j.authentication.password", neo4j::getAdminPassword);
}
@Test
void yourTest(@Autowired Driver driver) {
// Whatever is tested
}
}| 1 | Use the dedicated Neo4j test slice |
| 2 | Import this auto-configuration (which is not part of Spring Boot) |
| 3 | Bring up a container to test against |
| 4 | Use DynamicPropertySource for configuring the test resources dynamically |
4.4.2. Available configuration properties
The following configuration properties in the org.neo4j.migrations namespace are supported:
org.neo4j.migrations.check-location-
Whether to check that migration scripts location exists.
-
Type:
java.lang.Boolean -
Default:
true
-
org.neo4j.migrations.database-
The database that should be migrated (Neo4j EE 4.0+ only). Leave
nullfor using the default database.-
Type:
java.lang.String -
Default:
null
-
org.neo4j.migrations.schema-database-
The database that should be used for storing information about migrations (Neo4j EE 4.0+ only). Leave
nullfor using the default database.-
Type:
java.lang.String -
Default:
null
-
org.neo4j.migrations.impersonated-user-
An alternative user to impersonate during migration. Might have higher privileges than the user connected, which will be dropped again after migration. Requires Neo4j EE 4.4+. Leave
nullfor using the connected user.-
Type:
java.lang.String -
Default:
null
-
org.neo4j.migrations.enabled-
Whether to enable Neo4j-Migrations or not.
-
Type:
java.lang.Boolean -
Default:
true
-
org.neo4j.migrations.encoding-
Encoding of Cypher migrations.
-
Type:
java.nio.charset.Charset -
Default:
UTF-8
-
org.neo4j.migrations.installed-by-
Username recorded as property
byon theMIGRATED_TOrelationship.-
Type:
java.lang.String -
Default:
System user
-
org.neo4j.migrations.locations-to-scan-
Locations of migrations scripts.
-
Type:
java.lang.String[] -
Default:
[classpath:neo4j/migrations]
-
org.neo4j.migrations.packages-to-scan-
List of packages to scan for Java migrations.
-
Type:
java.lang.String[] -
Default:
[](an empty array)
-
org.neo4j.migrations.transaction-mode-
The transaction mode in use (Defaults to "per migration", meaning one script is run in one transaction).
-
Type:
TransactionMode -
Default:
PER_MIGRATION
-
org.neo4j.migrations.validate-on-migrate-
Validating helps you verify that the migrations applied to the database match the ones available locally and is on by default.
-
Type:
java.lang.Boolean -
Default:
true
-
org.neo4j.migrations.autocrlf-
Automatically convert Windows line-endings (CRLF) to LF when reading resource based migrations, pretty much what the same Git option does during checkin.
-
Type:
java.lang.Boolean -
Default:
false
-
org.neo4j.migrations.delay-between-migrations-
A configurable delay that will be applied in between applying two migrations.
-
Type:
java.time.Duration -
Default:
false
-
org.neo4j.migrations.version-sort-order-
How versions should be sorted. The default of
LEXICOGRAPHICwill change toSEMANTICin a future version of this library.-
Type:
ac.simons.neo4j.migrations.core.MigrationsConfig#VersionSortOrder -
Default:
LEXICOGRAPHIC
-
org.neo4j.migrations.out-of-order-
A flag to enable out-of-order migrations.
-
Type:
java.lang.Boolean -
Default:
false
-
org.neo4j.migrations.target-
Configures the target version up to which migrations should be considered. This must be a valid migration version, or one of the special values
current,latestornext.-
Type:
java.lang.String -
Default:
null
-
Migrations can be disabled by setting org.neo4j.migrations.enabled to false.
|
4.5. Quarkus
We provide an extension with automatic configuration for Quarkus. Declare the following dependency in your Quarkus application:
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-quarkus</artifactId>
<version>3.2.0</version>
</dependency>That extension itself depends on the Neo4j Java Driver and the corresponding Quarkus extension Quarkus-Neo4j and requires at least Quarkus 2.6. You don’t need to declare those dependencies, they are already transitive dependencies of this extension.
Neo4j-Migrations will automatically look for migrations in classpath:neo4j/migrations and will fail if this location does not exist.
It does not scan by default for Java-based migrations.
Here’s an example on how to configure the driver and the migrations:
quarkus.neo4j.uri=bolt://localhost:7687
quarkus.neo4j.authentication.username=neo4j
quarkus.neo4j.authentication.password=secret
org.neo4j.migrations.packages-to-scan=foo.barIf you disable Neo4j-Migrations via org.neo4j.migrations.enabled we won’t apply Migrations at startup but the Migrations object
will still be in the context to be used.
All other properties available for the Spring-Boot-Starter are available for the Quarkus extension, too.
Their namespace is the same: org.neo4j.migrations.
The module will also log some details about the product version and the database connected to. This can be disabled by setting the logger ac.simons.neo4j.migrations.core.Migrations.Startup to a level higher than INFO.
|
4.5.1. Build-time vs runtime config
org.neo4j.migrations.packages-to-scan and org.neo4j.migrations.locations-to-scan are build-time configuration options
and cannot be changed during runtime. This allows for optimized images to be created: All migrations that are part of the
classpath (both scripts and class based migrations) are discovered during image build-time already and are included in
the image themselves (this applies to both native and JVM images).
While scripts in file system locations (all locations starting with file://) are still discovered during runtime and thus
allows for scripts being added without recreating the application image, the location cannot be dynamically changed. If you
need a dynamic, file:// based location, use org.neo4j.migrations.external-locations. This property is changeable during
runtime and allows for one image being used in different deployments pointing to different external locations with scripts
outside the classpath
An alternative approach to that is using the CLI in a sidecar container, pointing to the dynamic location and keep applying database migrations outside the application itself.
4.5.2. Dev Services integration
Neo4j-Migrations will appear as a tile in the Quarkus Dev UI under http://localhost:8080/q/dev/. It provides a list of migrations which can be used to clean the database or apply all migrations. The latter is handy when migrate at start is disabled or in case there are callbacks that might reset or recreate testdata.
4.6. Maven-Plugin
You can trigger Neo4j-Migrations from your build a Maven-Plugin. Please refer to the dedicated Maven-Plugin page for a detailed list of all goals and configuration option as well as the default lifecycle mapping of the plugin.
4.6.1. Configuration
Most of the time you will configure the following properties for the plugin:
<plugin>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<configuration>
<user>neo4j</user>
<password>secret</password>
<address>bolt://localhost:${it-database-port}</address>
<verbose>true</verbose>
</configuration>
</execution>
</executions>
</plugin>All goals provide those properties.
By default, the plugin will look in neo4j/migrations for Cypher-based migrations.
You can change that via locationsToScan inside the configuration element like this:
<locationsToScan>
<locationToScan>file://${project.build.outputDirectory}/custom/path</locationToScan>
</locationsToScan>Add multiple locationToScan elements for multiple locations to scan.
4.6.2. Goals
All goals as described in Section 4.1 are supported.
-
clean, see Section 4.1.1
-
info, see Section 4.1.3
-
migrate, see Section 4.1.4
-
clean, see Section 4.1.6
The above list links to the corresponding Maven-Plugin page, please check those goals out for further details.
4.7. Defining and using catalogs
This chapter is more about conceptional usage or scenarios one can implement by using Catalog-based migrations. All scenarios can be executed with any of the previously explained APIS, being it the CLI, the Core API or within Spring Boot, Quarkus or Maven, except easily dumping a local or a remote catalog as XML or Cypher file.
Catalogs are a powerful mechanism to shape your database’s schema exactly the way you want it and this is only a small subset of possible scenarios that can be implemented.
For the rest of these steps we assume that you are using the CLI and used the init command to create a local directory structure
holding connection data such as URL and credentials as well as your migrations:
neo4j-migrations -a bolt://localhost:7687 -u neo4j -p secret init
tree -awhich will result in
.
├── .migrations.properties
└── neo4j
└── migrations
2 directories, 1 fileAll migrations we are going to work with will be stored in neo4j/migrations.
One sensible step before doing anything with the schema is to assert our local catalog meets the remote catalog as expected. In this example we assert toe remote catalog to be empty and we define our first migration like this:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<verify useCurrent="true"/> (1)
</migration>| 1 | useCurrent has been set to true to refer to the local catalog as defined in version 10, which is been empty,
exactly what we expect |
Applying this now via neo4j-migrations apply yields the following result:
[2022-06-01T15:13:39.997000000] Applied migration 010 ("Assert empty schema").
Database migrated to version 010.Of course this step is only executed once, when this migration is applied. If we add another one too it, that verification does not happen again, as the 010 has been applied. Therefore, a verification step can be added to each catalog based migration:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<catalog>
<constraints>
<constraint name="person_name_unique" type="unique">
<label>Person</label>
<properties>
<property>name</property>
</properties>
</constraint>
</constraints>
</catalog>
<verify/>
<create ref="person_name_unique"/>
</migration>Note that we didn’t specify useCurrent here. This means verification should happen based on the local catalog prior to
version 020. Applying this migration yields:
[2022-06-01T15:17:27.508000000] Skipping already applied migration 010 ("Assert empty schema")
[2022-06-01T15:17:27.771000000] Applied migration 020 ("Create person name unique").
Database migrated to version 020.A day later you figure out that a unique constraint on a persons names isn’t the best of all ideas, and you decide to fix that. Assuming for sake of sanity that every person has a name, we replace that uniqueness with an existential constraint.
Existential constraints are a Neo4j enterprise feature, so we must cater for that as well and we define two different files for the next version:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<?assume that edition is community ?>
<drop item="person_name_unique"/>
</migration>and for the enterprise edition, we can redefine the constraint like this:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<?assume that edition is enterprise ?>
<catalog>
<constraints>
<constraint name="person_name_unique" type="exists">
<label>Person</label>
<properties>
<property>name</property>
</properties>
</constraint>
</constraints>
</catalog>
<drop ref="person_name_unique"/>
<create ref="person_name_unique"/>
</migration>Note how we can refer to the constraint by ref in Listing 34 and how we must use
item in Listing 33. The reason for that is that we refer to an older item only in the
migration for community edition. We redefined the item in the script for the enterprise edition, so we might as well
refer to it.
In older Neo4j versions not supporting names for constraints Neo4j-Migrations will use the old definition to drop the item
in question.
Applying the current state now yields
[2022-06-01T16:04:46.446188000] Skipping 030 ("Fix person name constraint CE") due to unmet preconditions:
// assume that edition is COMMUNITY
[2022-06-01T16:04:46.493400000] Skipping already applied migration 010 ("Assert empty schema")
[2022-06-01T16:04:46.496401000] Skipping already applied migration 020 ("Create person name unique")
[2022-06-01T16:04:46.659585000] Applied migration 030 ("Fix person name constraint EE").
Database migrated to version 030.Assuming you some other enterprise stuff related items in the following listing:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<?assume that edition is enterprise ?>
<catalog>
<indexes/>
<constraints>
<constraint name="liked_day" type="exists">
<type>LIKED</type>
<properties>
<property>day</property>
</properties>
</constraint>
<constraint name="person_keys" type="key">
<label>Person</label>
<properties>
<property>firstname</property>
<property>surname</property>
</properties>
</constraint>
</constraints>
</catalog>
<create ref="liked_day"/>
<create ref="person_keys"/>
</migration>To get some information about your database, you can inspect the remote catalog:
neo4j-migrations show-catalogand it will print the catalog in XML:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<catalog>
<indexes/>
<constraints>
<constraint name="liked_day" type="unique">
<label>LIKED</label>
<properties>
<property>day</property>
</properties>
</constraint>
<constraint name="person_keys" type="key">
<label>Person</label>
<properties>
<property>firstname</property>
<property>surname</property>
</properties>
</constraint>
<constraint name="person_name_unique" type="exists">
<label>Person</label>
<properties>
<property>name</property>
</properties>
</constraint>
</constraints>
</catalog>
</migration>You can also get the catalog as Cypher with
neo4j-migrations show-catalog format=CYPHER version=4.4yielding
CREATE CONSTRAINT person_keys IF NOT EXISTS FOR (n:Person) REQUIRE (n.firstname, n.surname) IS NODE KEY;
CREATE CONSTRAINT liked_day IF NOT EXISTS FOR ()-[r:LIKED]-() REQUIRE r.day IS NOT NULL;
CREATE CONSTRAINT person_name_unique IF NOT EXISTS FOR (n:Person) REQUIRE n.name IS NOT NULL;Changing the version number to an older version will give the correct syntax, too:
> neo4j-migrations show-catalog format=CYPHER version=3.5
CREATE CONSTRAINT ON (n:Person) ASSERT (n.firstname, n.surname) IS NODE KEY;
CREATE CONSTRAINT ON ()-[r:LIKED]-() ASSERT exists(r.day);
CREATE CONSTRAINT ON (n:Person) ASSERT exists(n.name);After all, you decide it’s best not to stick with any constraint on the persons name and also drop your experiments.
You could use <apply /> to make your database look exactly like your catalog. But that would include all previously
defined items, too.
Therefore, you need to reset the catalog as shown in the following listing:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<catalog reset="true">
<constraints>
<constraint name="unique_person_id" type="unique">
<label>Person</label>
<properties>
<property>id</property>
</properties>
</constraint>
</constraints>
</catalog>
<apply/>
</migration>followed by a final verification:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<verify allowEquivalent="false"/>
</migration>Run the following commands to see the outcome:
neo4j-migrations applyapplies everything:
[2022-06-01T19:16:20.058218000] Skipping 030 ("Fix person name constraint CE") due to unmet preconditions:
// assume that edition is COMMUNITY
[2022-06-01T19:16:20.223937000] Skipping already applied migration 010 ("Assert empty schema")
[2022-06-01T19:16:20.225464000] Skipping already applied migration 020 ("Create person name unique")
[2022-06-01T19:16:20.225748000] Skipping already applied migration 030 ("Fix person name constraint EE")
[2022-06-01T19:16:20.226022000] Skipping already applied migration 040 ("Additional stuff")
[2022-06-01T19:16:20.501686000] Applied migration 050 ("A new start").
[2022-06-01T19:16:20.551983000] Applied migration 060 ("Assert final state").
Database migrated to version 060.neo4j-migrations show-catalog format=CYPHERpresents the remote catalog as
CREATE CONSTRAINT unique_person_id IF NOT EXISTS FOR (n:Person) REQUIRE n.id IS UNIQUE;and so does the local catalog
neo4j-migrations show-catalog format=CYPHER mode=LOCAL 2&>/dev/nullThe redirect is included here so that log messages on stderr are skipped (the message about one migration skipped due to unmet preconditions).
Appendix
Glossary
- Pending migration
-
See Resolved migration.
- Resolved migration
-
A migration that has been resolved in the classpath or the filesystem which has not been yet applied.
- Schema database
-
A database inside a Neo4j enterprise instance or cluster that stores the schema information from Neo4j-Migrations.
- Target database
-
A database inside a Neo4j enterprise instance or cluster that is refactored by Neo4j-Migrations.
XML Schemes
migration.xsd
Before we jump into the pure joy of an XML Schema, lets read in plain english what our schema can do:
-
A
<migration />can have zero or exactly one<catalog />element. -
A
<catalog />consists of zero or one<constraints />and zero or one<indexes />elements. In addition, it can indicate aresetattribute, replacing the current known content with the catalog currently being in definition. -
Both of them can contain zero or more of their individual elements, according to their definition.
-
A
<migration />can have zero or one<verify />operations and the<verify />operation must be the first operation. -
A
<migration />can than have zero or more<create />and<drop />operations or exactly one<apply />operation. The<apply />operation is mutual exclusive to all operations working on single items. -
Operations that work on a single item (create and drop) are allowed to define a single item locally. This item won’t participate in the global catalog.
-
Operations that work on a single item can refer to this item by either using the attribute
item(a free form string) orref(anxs:IDREF). While the latter is useful for referring to items defined in the same migration (it will usually be validated by your tooling), the former is handy to refer to items defined in other migrations.
A catalog item will either have a child-element <label /> in which case it will always refer to nodes or a mutual
exclusive child-element <type /> in which it always refers to relationships. The type attribute is unrelated
to the target entity. This attribute defines the type of the element (such as unique- or existential constraints).
We do support the following processing instructions:
-
<?assert followed by a valid precondition ?> -
<?assume followed by a valid precondition ?>
Look up valid preconditions here. The full XMl schema for catalog-based migrations looks like this:
<?xml version="1.0" encoding="UTF-8" ?>
<!--
Copyright 2020-2026 the original author or authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="https://michael-simons.github.io/neo4j-migrations"
xmlns="https://michael-simons.github.io/neo4j-migrations"
elementFormDefault="qualified">
<xs:element name="migration" type="migration"/>
<xs:complexType name="migration">
<xs:sequence>
<xs:element name="catalog" minOccurs="0" type="catalog"/>
<xs:element name="verify" minOccurs="0" type="verifyOperation" />
<xs:choice>
<xs:choice maxOccurs="unbounded">
<xs:element name="refactor" minOccurs="0" maxOccurs="unbounded" type="refactoring"/>
<xs:choice maxOccurs="unbounded">
<xs:element name="create" minOccurs="0" maxOccurs="unbounded" type="createOperation"/>
<xs:element name="drop" minOccurs="0" maxOccurs="unbounded" type="dropOperation"/>
</xs:choice>
</xs:choice>
<xs:element name="apply" minOccurs="0" type="applyOperation"/>
</xs:choice>
</xs:sequence>
</xs:complexType>
<xs:complexType name="refactoring">
<xs:sequence minOccurs="0">
<xs:element name="parameters">
<xs:complexType>
<xs:sequence maxOccurs="unbounded">
<xs:any processContents="lax"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="type">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="merge.nodes"/>
<xs:enumeration value="migrate.createFutureIndexes"/>
<xs:enumeration value="migrate.replaceBTreeIndexes"/>
<xs:enumeration value="normalize.asBoolean"/>
<xs:enumeration value="rename.label"/>
<xs:enumeration value="rename.type"/>
<xs:enumeration value="rename.nodeProperty"/>
<xs:enumeration value="rename.relationshipProperty"/>
<xs:enumeration value="addSurrogateKeyTo.nodes"/>
<xs:enumeration value="addSurrogateKeyTo.relationships"/>
<xs:enumeration value="listToVectorOn.nodes"/>
<xs:enumeration value="listToVectorOn.relationships"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
<xs:complexType name="catalog">
<xs:all>
<xs:element name="constraints" minOccurs="0">
<xs:complexType>
<xs:sequence>
<xs:element type="constraint" name="constraint"
maxOccurs="unbounded" minOccurs="0"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="indexes" minOccurs="0">
<xs:complexType>
<xs:sequence>
<xs:element type="index" name="index"
maxOccurs="unbounded" minOccurs="0"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:all>
<xs:attribute name="reset" type="xs:boolean" default="false"/>
</xs:complexType>
<xs:complexType name="operation" />
<xs:complexType name="applyOperation">
<xs:complexContent>
<xs:extension base="operation" />
</xs:complexContent>
</xs:complexType>
<xs:complexType name="verifyOperation">
<xs:complexContent>
<xs:extension base="operation" >
<xs:attribute name="useCurrent" type="xs:boolean" default="false"/>
<xs:attribute name="allowEquivalent" type="xs:boolean" default="true"/>
<xs:attribute name="includeOptions" type="xs:boolean" default="false"/>
</xs:extension>
</xs:complexContent>
</xs:complexType>
<xs:complexType name="itemOperation">
<xs:complexContent>
<xs:extension base="operation">
<xs:sequence>
<xs:choice minOccurs="0">
<xs:element name="constraint" type="constraint"/>
<xs:element name="index" type="index"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="item" type="xs:string"/>
<xs:attribute name="ref" type="xs:IDREF"/>
</xs:extension>
</xs:complexContent>
</xs:complexType>
<xs:complexType name="createOperation">
<xs:complexContent>
<xs:extension base="itemOperation">
<xs:attribute name="ifNotExists" type="xs:boolean" default="true"/>
</xs:extension>
</xs:complexContent>
</xs:complexType>
<xs:complexType name="dropOperation">
<xs:complexContent>
<xs:extension base="itemOperation">
<xs:attribute name="ifExists" type="xs:boolean" default="true"/>
</xs:extension>
</xs:complexContent>
</xs:complexType>
<xs:complexType name="property">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="type">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="BOOLEAN"/>
<xs:enumeration value="STRING"/>
<xs:enumeration value="INTEGER"/>
<xs:enumeration value="FLOAT" />
<xs:enumeration value="DATE" />
<xs:enumeration value="LOCAL TIME" />
<xs:enumeration value="ZONED TIME" />
<xs:enumeration value="LOCAL DATETIME" />
<xs:enumeration value="ZONED DATETIME" />
<xs:enumeration value="DURATION" />
<xs:enumeration value="POINT" />
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="properties">
<xs:sequence>
<xs:element type="property" name="property" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="catalogItem">
<xs:attribute name="name" use="required" type="xs:ID"/>
</xs:complexType>
<xs:complexType name="constraint">
<xs:complexContent>
<xs:extension base="catalogItem">
<xs:sequence>
<xs:choice>
<xs:element name="label" type="xs:string"/>
<xs:element name="type" type="xs:string"/>
</xs:choice>
<xs:element type="properties" name="properties"/>
<xs:element type="xs:string" name="options" minOccurs="0"/>
</xs:sequence>
<xs:attribute name="type" use="required">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="unique"/>
<xs:enumeration value="unique_relationship_property"/>
<xs:enumeration value="exists"/>
<xs:enumeration value="key"/>
<xs:enumeration value="property_type" />
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:extension>
</xs:complexContent>
</xs:complexType>
<xs:complexType name="index">
<xs:complexContent>
<xs:extension base="catalogItem">
<xs:sequence>
<xs:choice>
<xs:element name="label" type="xs:string"/>
<xs:element name="type" type="xs:string"/>
</xs:choice>
<xs:element type="properties" name="properties"/>
<xs:element type="xs:string" name="options" minOccurs="0"/>
</xs:sequence>
<xs:attribute name="type">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="property" />
<xs:enumeration value="fulltext"/>
<xs:enumeration value="text"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:extension>
</xs:complexContent>
</xs:complexType>
</xs:schema>Refactorings
Neo4j-Migrations contains a set of ready-to-use database refactorings. These refactorings are all modelled very closely to those available in APOC but none of them requires APOC to be installed in your database. The refactorings are mostly designed to work from within a catalog but they work very well on their own to. While they are part of the Core API, they don’t depend on a Migration instance. Their API is subject to the same versioning guarantees as the rest of Neo4j-Migrations. Refactorings might evolve into a their module at a later point in time.
Some refactorings require certain Neo4j versions. If you do support multiple Neo4j versions, define those refactorings as single itemed migrations and add assumptions like in the following example:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<?assume that version is ge 4.1 ?>
<refactor type="normalize.asBoolean">
<parameters>
<parameter name="property">watched</parameter>
<parameter name="trueValues">
<value>y</value>
<value>YES</value>
</parameter>
<parameter name="falseValues">
<value>n</value>
<value>NO</value>
</parameter>
</parameters>
</refactor>
</migration>Applying refactorings programmatically
While you would normally use the declarative approach of applying refactorings from within XML / catalog based migrations, Neo4j-Migrations offers an API for it as well:
try (Session session = driver.session()) {
session.run("CREATE (m:Person {name:'Michael'}) -[:LIKES]-> (n:Person {name:'Tina', klug:'ja'})"); (1)
}
Migrations migrations = new Migrations(MigrationsConfig.defaultConfig(), driver); (2)
Counters counters = migrations.apply(
Rename.type("LIKES", "MAG"), (3)
Normalize.asBoolean("klug", List.of("ja"), List.of("nein"))
);
try (Session session = driver.session()) {
long cnt = session
.run("MATCH (m:Person {name:'Michael'}) -[:MAG]-> (n:Person {name:'Tina', klug: true}) RETURN count(m)")
.single().get(0).asLong();
assert cnt == 1
}| 1 | The graph that will be refactored |
| 2 | You can create the instance as shown here or use the existing one when you already use the Spring Boot starter or the Quarkus extensions |
| 3 | Build as many refactorings as needed, they will be applied in order. You can use the counters to check for the numbers of modifications |
Merging nodes
Merge.nodes(String source, List<PropertyMergePolicy> mergePolicies) merges all the nodes, their properties and relationships onto a single node (the first in the list of matched nodes). It is important that your query uses an ordered return for this to work proper.
The Merge refactoring requires Neo4j 4.4+.
As catalog item:
<refactor type="merge.nodes">
<parameters>
<parameter name="sourceQuery">MATCH (p:Person) RETURN p ORDER BY p.name ASC</parameter>
<!-- Repeat as often as necessary -->
<parameter name="mergePolicy">
<pattern>name</pattern>
<strategy>KEEP_LAST</strategy>
</parameter>
<parameter name="mergePolicy">
<pattern>.*</pattern>
<strategy>KEEP_FIRST</strategy>
</parameter>
</parameters>
</refactor>Normalizing
Normalizing is the process to take an humongous set of properties and other Graph Items and apply a scheme to it. The normalizing refactoring requires at least Neo4j 4.1, running it with batches requires Neo4j 4.4 or higher.
Normalize properties as boolean
Often times database schemes evolved over time, and you find properties with a boolean meaning and a string datatype with content such as ja, HiddenB, yes, NO or literal null. To use them proper in queries, you might want to normalize them into a real boolean value. This is done with Normalize.asBoolean.
Normalize.asBoolean takes in the name of a property and a list of values that are treated as true and a list of values that are treated as false. A property with a value that is not in any of those lists will be deleted. null as value is a non-existent property. However, if either lists contains literal null, a property will be created with the corresponding value.
By default all properties of all nodes and relationships will be normalized. To only apply this refactoring to a subset, i.e. only to nodes, you would want to use a custom query.
A Java example looks like this:
Normalize.asBoolean(
"watched",
List.of("y", "YES", "JA"),
// List.of does not support literal null,
// so we need to this the old-school
Arrays.asList("n", "NO", null)
);The same as a catalog item:
<refactor type="normalize.asBoolean">
<parameters>
<parameter name="property">watched</parameter>
<parameter name="trueValues">
<value>y</value>
<value>YES</value>
<value>JA</value>
</parameter>
<parameter name="falseValues">
<value>n</value>
<value>NO</value>
<value />
</parameter>
<!-- Optional custom query and batch size -->
<!--
<parameter name="customQuery">MATCH (n:Movie) return n</parameter>
<parameter name="batchSize">42</parameter>
-->
</parameters>
</refactor>Renaming labels, types and properties
ac.simons.neo4j.migrations.core.refactorings.Rename renames labels, types and properties and requires in its default form only Neo4j 3.5 to work. Custom queries for filtering target entities require Neo4j 4.1, batches Neo4j 4.4.
Common methods
inBatchesOf-
Enables or disables batching, requires Neo4j 4.4
withCustomQuery-
Provides a custom query matching an entity (Node or Label) for renaming. The query must return zero or more rows each containing one item. This feature requires Neo4j 4.1
Renaming labels
Rename.label(String from, String to) renames all labels on all nodes that are equal the value of from to the value of to.
As catalog item:
<refactor type="rename.label">
<parameters>
<parameter name="from">Engineer</parameter>
<parameter name="to">DevRel</parameter>
<!-- Optional custom query -->
<!--
<parameter name="customQuery"><![CDATA[
MATCH (person:Engineer)
WHERE person.name IN ["Mark", "Jennifer", "Michael"]
RETURN person
]]></parameter>
-->
<!-- Optional batch size (requires Neo4j 4.4+) -->
<!--
<parameter name="batchSize">23</parameter>
-->
</parameters>
</refactor>Renaming types
Rename.type(String from, String to) renames all types on all relationships that are equal the value of from to the value of to.
As catalog item:
<refactor type="rename.type">
<parameters>
<parameter name="from">COLLEAGUES</parameter>
<parameter name="to">FROLLEAGUES</parameter>
<!-- Optional custom query -->
<!--
<parameter name="customQuery"><![CDATA[
MATCH (:Engineer {name: "Jim"})-[rel]->(:Engineer {name: "Alistair"})
RETURN rel
]]></parameter>
-->
<!-- Optional batch size (requires Neo4j 4.4+) -->
<!--
<parameter name="batchSize">23</parameter>
-->
</parameters>
</refactor>Renaming node properties
Rename.nodeProperty(String from, String to) renames all properties on all nodes that are equal the value of from to the value of to.
As catalog item:
<refactor type="rename.nodeProperty">
<parameters>
<parameter name="from">released</parameter>
<parameter name="to">veröffentlicht im Jahr</parameter>
<!-- Optional custom query -->
<!--
<parameter name="customQuery"><![CDATA[
MATCH (n:Movie) WHERE n.title =~ '.*Matrix.*' RETURN n
]]></parameter>
-->
<!-- Optional batch size (requires Neo4j 4.4+) -->
<!--
<parameter name="batchSize">23</parameter>
-->
</parameters>
</refactor>Renaming type properties
Rename.typeProperty(String from, String to) renames all properties on all relationships that are equal the value of from to the value of to.
As catalog item:
<refactor type="rename.relationshipProperty">
<parameters>
<parameter name="from">roles</parameter>
<parameter name="to">rollen</parameter>
<!-- Optional custom query -->
<!--
<parameter name="customQuery"><![CDATA[
MATCH (n:Movie) <-[r:ACTED_IN] -() WHERE n.title =~ '.*Matrix.*' RETURN r
]]></parameter>
-->
<!-- Optional batch size (requires Neo4j 4.4+) -->
<!--
<parameter name="batchSize">23</parameter>
-->
</parameters>
</refactor>Adding surrogate keys
You can use Neo4j-Migrations to add Surrogate Keys aka technical keys to your Nodes and Relationships. This is especially helpful to migrate away from internal Neo4j ids, such as id() (Neo4j 4.4 and earlier) or elementId(). While these functions are useful and several Object-Graph-Mappers can use them right out of the box, they are often not what you want:
-
You expose database internals as proxy for your own technical keys
-
Your business now is dependent on the way the database generates them
-
They might get reused (inside Neo4j), leaving you with no good guarantees for an identifier
Our build-in refactorings use randomUUID() to assign a UUID to a property named id for Nodes with a given set of labels or Relationships with a matching type for which such a property does not exist. Both the generator and the name of the property can be individually configured. Also, both type of entities can be matched with a custom query.
Movie Nodes (XML)<refactor type="addSurrogateKeyTo.nodes">
<parameters>
<parameter name="labels">
<value>Movie</value>
</parameter>
</parameters>
</refactor>Movie Nodes (Java)var addSurrogateKey = AddSurrogateKey.toNodes("Movie");ACTED_IN relationships (XML)<refactor type="addSurrogateKeyTo.relationships">
<parameters>
<parameter name="type">ACTED_IN</parameter>
</parameters>
</refactor>ACTED_IN relationships (Java)var addSurrogateKey = AddSurrogateKey.toRelationships("ACTED_IN");The following examples use a different target property and hard-copy the internal id into a property. Of course, you can use your own user-defined functions for generating keys. A single %s will be replaced with a variable holding the matched entity. The syntax for relationships is the same (as demonstrated above):
<refactor type="addSurrogateKeyTo.nodes">
<parameters>
<parameter name="labels">
<value>Movie</value>
</parameter>
<parameter name="property">movie_pk</parameter>
<parameter name="generatorFunction">id(%s)</parameter>
</parameters>
</refactor>var addSurrogateKey = AddSurrogateKey.toNodes("Movie")
.withProperty("movie_pk")
.withGeneratorFunction("id(%s)");Converting list of numbers to Vector types
This refactoring requires a database that supports CYPHER 25 and native vector types. As of writing all enterprise edition of Neo4j >= Neo4j 2025.10 are applicable.
|
Neo4j 2025.10 introduced the Vector Types.
Prior to that type, db.create.setNodeVectorProperty and db.create.setRelationshipVectorProperty would create properties of type LIST<FLOAT NOT NULL> NOT NULL.
While these properties are still supported in current vector indexes, you might want to migrate them to VECTOR<FLOAT NOT NULL>(n) NOT NULL where n is the size of the vector.
Use listToVectorOn.nodes and listToVectorOn.relationships for that.
This refactoring allows basically for the same customization as AddSurrogateKey above and can be used either via an XML based catalog or programmatically.
embedding properties on Nodes labelled Movie to a VECTOR<refactor type="listToVectorOn.nodes">
<parameters>
<parameter name="labels">
<value>Movie</value>
</parameter>
</parameters>
</refactor>The refactoring assumes a property name of embedding by default, which of course can be configured, too:
einbettung properties on Nodes labelled Movie to a VECTOR<refactor type="listToVectorOn.nodes">
<parameters>
<parameter name="labels">
<value>Movie</value>
</parameter>
<parameter name="property">einbettung</parameter>
</parameters>
</refactor>The following example works on relationships and uses Cypher INTEGER32 type for the vector. Be aware that your data must fit that datatype, otherwise the DBMS will error out:
<refactor type="listToVectorOn.relationships">
<parameters>
<parameter name="type">
<value>ACTED_IN</value>
</parameter>
<parameter name="elementType">INTEGER32</parameter>
</parameters>
</refactor>The algorith will only work on entities that have a property with the given name and the type LIST<FLOAT NOT NULL> NOT NULL and not touch anything else.
Feel free to use a custom query for matching entities.
Migrating BTREE indexes to "future" indexes
Neo4j 4.4 introduces future indexes, RANGE and POINT which replace the well known BTREE indexes of Neo4j 4.x. These new indexes are available from Neo4j 4.4 onwards but will not participate in any query planing in Neo4j 4.4. They exist merely for migration purposes in Neo4j 4.4: Neo4j 5.0 does not support BTREE indexes at all. This means a database that contains BTREE indexes cannot be upgraded to Neo4j 5.0. Existing BTREE indexes need to be dropped prior to attempting the upgrade. The class ac.simons.neo4j.migrations.core.refactorings.MigrateBTreeIndexes has been created for this purpose. It allows creation of matching new indexes and optionally dropping the indexes that are no longer supported in Neo4j 5.0 and higher prior to upgrading the store.
As with all the other refactorings, it can be used programmatically in your own application or through Neo4j-Migrations.
Preparing an upgrade to Neo4j 5.0 by creating future indexes in parallel
<refactor type="migrate.createFutureIndexes">
<parameters> (1)
<parameter name="suffix">_future</parameter> (2)
<parameter name="excludes"> (3)
<value>a</value>
<value>b</value>
</parameter>
<parameter name="typeMapping"> (4)
<mapping>
<name>c</name>
<type>POINT</type>
</mapping>
<mapping>
<name>d</name>
<type>TEXT</type>
</mapping>
</parameter>
</parameters>
</refactor>| 1 | All parameters are optional |
| 2 | The default suffix is _new |
| 3 | An excludes list can be used to exclude items from being processed by name. Its pendant is the includes list. If
the latter is not empty, only the items in the list will be processed |
| 4 | By default, RANGE indexes are created. The type mapping allows to map specific old indexes to either RANGE, POINT or TEXT.
The type mappings are not consulted when migrating constraint-backing indexes. |
When the above refactoring is applied, new indexes and constraints will be created in parallel to the old ones. The refactoring will log statements for dropping the old constraints.
Preparing an upgrade to Neo4j 5.0 by replacing BTREE indexes with future indexes
The advantage of this approach is the fact that it won’t need additional manual work before doing a store upgrade. However, the store upgrade should follow closely after dropping the old indexes and creating the replacement indexes as the latter won’t participate in planning at all prior to the actual upgrade to Neo4j 5.0 or higher.
BTREE indexes with future indexes<refactor type="migrate.replaceBTreeIndexes">
<parameters>
<parameter name="includes">
<value>x</value>
<value>y</value>
</parameter>
</parameters>
</refactor>The suffix parameter is not supported as it is not needed. The other parameters have the same meaning as with migrate.createFutureIndexes. The above example shows the includes parameter.
Annotation processing
Neo4j-Migrations offers annotation processing for SDN 6 and generates catalogs containing unique constraints for all @Node entities using either assigned or externally generated ids (via @Id plus an optional external @GeneratedValue or without further annotation).
This is in line with recommended best practices for SDN 6:
-
Use externally assigned or generated IDs instead of Neo4j internal id values (especially when making those ids available to external systems)
-
Create at least indexes for them, better unique constraint to ensure that any assigned value is fit for its purpose
For more ideas and ruminations around that, please have a look at How to choose an unique identifier for your database entities. While that article is still from an SDN5+OGM perspective, it’s core ideas still apply.
The annotation processor is available under the following coordinates:
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-annotation-processor</artifactId>
<version>3.2.0</version>
</dependency>It has no dependencies apart from Neo4j-Migrations itself (neither SDN6 nor Neo4j-OGM), so it is safe to use it either directly as dependency so that it will be picked up by all recent Java compilers or as dedicated processor for the compiler:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<annotationProcessorPaths>
<annotationProcessorPath>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-annotation-processor</artifactId>
<version>3.2.0</version>
</annotationProcessorPath>
</annotationProcessorPaths>
<compilerArgs>
<arg>-Aorg.neo4j.migrations.catalog_generator.default_catalog_name=R${next-migration-version}__Create_sdn_constraints.xml</arg>
<arg>-Aorg.neo4j.migrations.catalog_generator.output_dir=my-generated-migrations</arg>
</compilerArgs>
</configuration>
</plugin>The latter approach allows for passing additional configuration to the processor, such as the output location relativ to target/generated-sources and various name generators.
There is a limited API to the processor living in the neo4j-migrations-annotation-processor-api module, such as ac.simons.neo4j.migrations.annotations.proc.ConstraintNameGenerator and the CatalogNameGenerator.
You can provide implementations, but they must live outside the project that is being subject to compilation, as otherwise those classes can’t be loaded by us.
All implementations must provide a default, publicly accessible constructor or - if they take in any nested options - a public constructor taking in exactly one argument of type Map<String, String>.
The scope of the generator is limited on purpose: It will generate a valid catalog declaration and by default an <apply /> operation. The latter is safe todo because catalogs are internally bound to their migration version and elements added or changed in v2 of a catalog will be appended, no elements will be deleted from the known catalog. Optionally the generator can be configured to generate a reset catalog, which will start the catalog at the given version fresh.
The generator does not generate a migration in a known migrations directory nor does it use a name that will be picked up Neo4j-Migrations by default. It is your task to configure the build system in such a way that any generated migration will
-
have a recognized naming schema
-
a name that evaluates to a correctly ordered version number
-
be part of the directories in the target that are configured to be picked by Neo4j-Migrations
Taking the above configuration of the processor one exemplary way to take this further is this:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<executions>
<execution>
<id>copy-resources</id>
<goals>
<goal>copy-resources</goal>
</goals>
<phase>process-classes</phase>
<configuration>
<outputDirectory>${project.build.outputDirectory}/neo4j/migrations/</outputDirectory>
<resources>
<resource>
<directory>${project.build.directory}/generated-sources/annotations/my-generated-migrations</directory>
<filtering>false</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>This works in our examples but bear in mind: The migration will always be regenerated. This is fine as long as you don’t change your annotated model in any capacity that results in a new or modified index (renaming attributes, labels etc.).
The generator will always use idempotent versions of indexes if available in your database. They work well with repeatable migrations.
So one solution is to configure the generator that it generates a name like R1_2_3__Create_domain_indexes.xml.
|
One approach is to add the processor to your build and run a diff with the last "good" generated catalog and the new one. If it is different, add the new catalog under an incremented version number.
A simpler approach is using a name generator that is connected to your target dev-database using a Migrations instance and our api (MigrationChain info = migrations.info(MigrationChain.ChainBuilderMode.REMOTE);) to get the latest applied version from the info instance (via .getLastAppliedVersion) and take that and increment it and just add the catalog fresh with a new version if it has change, otherwise resuse the old name.
For the naming generation APIs are provided and for the rest, maven-resources-plugin and maybe build-helper-maven-plugin are helpful. The decision to delegate that work has been made as it is rather difficult to propose a one-size-fits-all solution within this tool for all the combinations of different setups and build-systems out there.
Options can be passed to name generators via -Aorg.neo4j.migrations.catalog_generator.naming_options=<nestedproperties> with nestedproperties following a structure like a=x,b=y and so on. If you want to use that, your own name generator must provide a public constructor taking in one single Map<String, String> argument.
Our recommended approach is to use javac directly and script it’s invocation in your CI/CD system
as shown in the following paragraph!
|
Additional annotations
We offer a set of additional annotations - @Unique, @Required and @Fulltext that can be used standalone or together with SDN6 or OGM to specify constraints on classes. Please check the JavaDoc of those annotations about their usage. The module as shown below has no dependencies, neither on Neo4j-Migrations, nor SDN6 or OGM. While it works excellent with SDN6 for specifying additional information, all annotations offer a way to define labels and relationship types.
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-annotation-catalog</artifactId>
<version>3.2.0</version>
</dependency>Combined with SDN6, a valid definition would look like this:
import java.util.UUID;
import org.springframework.data.neo4j.core.schema.GeneratedValue;
import org.springframework.data.neo4j.core.schema.Id;
import org.springframework.data.neo4j.core.schema.Node;
import ac.simons.neo4j.migrations.annotations.catalog.Required;
import ac.simons.neo4j.migrations.annotations.catalog.Unique;
@Node
public record Organization(
@Id @GeneratedValue @Unique UUID id, (1)
@Required String name) {
}| 1 | Technically, the @Unique annotation isn’t necessary here and the processor will generate a constraint for that field out of the box, but we think it reads better that way. |
Using Javac and our annotation processor
The annotation processor itself is made of 3 artifacts:
neo4j-migrations-3.2.0.jar-
Needed to generate the catalogs
neo4j-migrations-annotation-processor-api-3.2.0.jar-
Contains the API and built-in annotations
neo4j-migrations-annotation-processor-3.2.0.jar-
The processor itself
You need to make sure to include all of them in the processor path, otherwise you will most likely read something like error: Bad service configuration file, or exception thrown while constructing Processor object: javax.annotation.processing.Processor: ac.simons.neo4j.migrations.annotations.proc.impl.CatalogGeneratingProcessor Unable to get public no-arg constructor, which is a bit misleading.
For OGM entities
You need at least neo4j-ogm-core as dependency for processing Neo4j-OGM entities and most likely all libraries that you are used in addition to OGM annotations in those entities. The following statement generates V01__Create_OGM_schema.xml in a directory output. It only does annotation processing:
javac -proc:only \
-processorpath neo4j-migrations-3.2.0.jar:neo4j-migrations-annotation-processor-api-3.2.0.jar:neo4j-migrations-annotation-processor-3.2.0.jar \
-Aorg.neo4j.migrations.catalog_generator.output_dir=output \
-Aorg.neo4j.migrations.catalog_generator.default_catalog_name=V01__Create_OGM_schema.xml \
-cp neo4j-ogm-core-4.0.0.jar \
extensions/neo4j-migrations-annotation-processing/processor/src/test/java/ac/simons/neo4j/migrations/annotations/proc/ogm/*For SDN Entities
The only difference here is that you must use SDN 6.0+ and its dependencies as a dependencies to JavaC:
javac -proc:only \
-processorpath neo4j-migrations-3.2.0.jar:neo4j-migrations-annotation-processor-api-3.2.0.jar:neo4j-migrations-annotation-processor-3.2.0.jar \
-Aorg.neo4j.migrations.catalog_generator.output_dir=output \
-Aorg.neo4j.migrations.catalog_generator.default_catalog_name=V01__Create_SDN6_schema.xml \
-cp apiguardian-api-1.1.2.jar:spring-data-commons-2.7.2.jar:spring-data-neo4j-6.3.2.jar \
extensions/neo4j-migrations-annotation-processing/processor/src/test/java/ac/simons/neo4j/migrations/annotations/proc/sdn6/movies/*For classes annotated with catalog annotations
No additional jars apart from the dedicated annotations are necessary
javac -proc:only \
-processorpath neo4j-migrations-3.2.0.jar:neo4j-migrations-annotation-processor-api-3.2.0.jar:neo4j-migrations-annotation-processor-3.2.0.jar \
-Aorg.neo4j.migrations.catalog_generator.output_dir=output \
-Aorg.neo4j.migrations.catalog_generator.default_catalog_name=R01__Create_annotated_schema.xml \
-cp neo4j-migrations-annotation-catalog-3.2.0 \
extensions/neo4j-migrations-annotation-processing/processor/src/test/java/ac/simons/neo4j/migrations/annotations/proc/catalog/valid/CoffeeBeanPure*Neo4j 5.9+ property type constraints
The annotation processor can create property type constraints from OGM and SDN models.
These constraints will ensure that the database schema enforces the datatypes declared in the models.
To enable that feature, configure the processor with -Aorg.neo4j.migrations.catalog_generator.generate_type_constraints=true`
Extensions
CSV Support (Experimental)
What does it do?
This module consists of some abstract bases classes that helps you to use data in CSV files during migration. The idea is that you have some CSV data you want to use LOAD CSV. Depending on whether the data has been changed or not, you need want to repeat the migration or not.
We have basically everything in place:
-
Java based migrations that can be repeated or not
-
Check-summing based on whatever.
What we can do for you is check-summing CSV data on HTTP urls for you. What you need to do is make them available to both Neo4j and this tool and provide a query to deal with them. Our tooling brings it together. Essentially, you want to inherit from ac.simons.neo4j.migrations.formats.csv.AbstractLoadCSVMigration like this:
import java.net.URI;
import ac.simons.neo4j.migrations.formats.csv.AbstractLoadCSVMigration;
import org.neo4j.driver.Query;
public class R050__LoadBookData extends AbstractLoadCSVMigration {
public R050__LoadBookData() {
super(URI.create("https://codeberg.org/michael-simons/goodreads/raw/branch/main/all.csv"), true);
}
@Override
public Query getQuery() {
// language=cypher
return new Query("""
LOAD CSV WITH HEADERS FROM '%s' AS row FIELDTERMINATOR ','
MERGE (b:Book {title: trim(row.Title)})
SET b.type = row.Type, b.state = row.State
WITH b, row
UNWIND split(row.Author, '&') AS author
WITH b, split(author, ',') AS author
WITH b, ((trim(coalesce(author[1], '')) + ' ') + trim(author[0])) AS author
MERGE (a:Person {name: trim(author)})
MERGE (a)-[r:WROTE]->(b)
WITH b, a
WITH b, collect(a) AS authors
RETURN b.title, b.state, authors
""");
}
}In the above example, we decide that the CSV data might change and therefor we indicate this migration being repeatable in the constructor call. If this is the case, we suggest using a class name reflecting that. If you use false during construction, migrations will fail if the data changes. The Cypher being used here does a merge and therefor, we added constraints to the title and person names beforehand. You may choose to omit the %s in the query template, but we suggest to use for the URI.
AsciiDoctor Support (Experimental)
What does it do?
Please open this README.adoc not only in a rendered view, but have a look at the raw asciidoc version!
|
When added to one of the supported use-case scenarios as an external library, it allows Neo4j-Migrations to discover AsciiDoctor files and use them as sources of Cypher statements for defining refactorings.
An AsciiDoctor based migration can have zero to many code blocks of type cypher with an id matching our versioning scheme
and valid inline Cypher content. The block definition looks like this:
[source,cypher,id=V1.0__Create_initial_data]
----
// Your Cypher based migration
----In fact, this README.adoc is a source of migrations on its own. It contains the following refactorings:
CREATE (a:Author {
id: randomUUID(),
name: 'Stephen King'
})
CREATE (b:Book {
id: randomUUID(),
name: 'The Dark Tower'
})
CREATE (a)-[:WROTE]->(b)We can have as many migrations as we want.
MATCH (a:Author {
name: 'Stephen King'
})
CREATE (b:Book {
id: randomUUID(),
name: 'Atlantis'
})
CREATE (a)-[:WROTE]->(b);
CREATE (a:Author {
id: randomUUID(),
name: 'Grace Blakeley'
})
CREATE (b:Book {
id: randomUUID(),
name: 'Stolen: How to Save the World From Financialisation'
})
CREATE (a)-[:WROTE]->(b);And to make queries on peoples name perform fast, we should add some indexes and constraints.
This we do with a separate document, V1.2__Create_id_constraints.xml to be included here:
<?xml version="1.0" encoding="UTF-8"?>
<migration xmlns="https://michael-simons.github.io/neo4j-migrations">
<catalog>
<indexes>
<index name="idx_author_name">
<label>Author</label>
<properties>
<property>name</property>
</properties>
</index>
<index name="idx_book_name">
<label>Book</label>
<properties>
<property>name</property>
</properties>
</index>
</indexes>
<constraints>
<constraint name="unique_id_author" type="unique">
<label>Author</label>
<properties>
<property>id</property>
</properties>
</constraint>
<constraint name="unique_id_book" type="unique">
<label>Book</label>
<properties>
<property>id</property>
</properties>
</constraint>
</constraints>
</catalog>
<apply/>
</migration>|
Includes are not processed. To make the system process the above xml content respectively any included Cypher
file, these files must live in a configured location, as described in the manual.
We opted against resolving includes for two reasons: It’s easier to reason about the sources of migrations when just inline code is processed and also, inclusion of arbitrary URLs may expose a security risk. Please have a look at the source of this file itself to understand what works and what not. |
The following block is an example of an included Cypher file, that will be used from its own location when this changeset is applied, but can still be referenced in this documentation:
CREATE (m:User {
name: 'Michael'
})
WITH m
MATCH (a:Author {
name: 'Stephen King'
})-[:WROTE]->(b)
WITH m, a, collect(b) AS books
CREATE (m)-[:LIKES]->(a)
WITH m, books
UNWIND books AS b
CREATE (m)-[:LIKES]->(b);The checksum of AsciiDoctor based migrations is computed individually per Cypher block, not for the whole file. So one AsciiDoctor file basically behaves as a container for many migrations.
How to use it?
The extension is loaded via service loader. In a standard Spring Boot or Quarkus application you just need to add one additional dependency:
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-formats-adoc</artifactId>
<version>3.2.0</version>
</dependency>Or in case you fancy Gradle:
dependencies {
implementation 'eu.michael-simons.neo4j:neo4j-migrations-formats-adoc:3.2.0'
}And that’s all.
For the CLI, you should download the -all artifact from Maven Central: neo4j-migrations-formats-adoc-3.2.0-all.jar
This will work only with the JVM based CLI version, which is available here.
A full example looks like this:
curl -LO https://github.com/michael-simons/neo4j-migrations/releases/download/3.2.0/neo4j-migrations-3.2.0.zip
curl -LO https://repo.maven.apache.org/maven2/eu/michael-simons/neo4j/neo4j-migrations-formats-adoc/3.2.0/neo4j-migrations-formats-adoc-3.2.0-all.jar
unzip neo4j-migrations-3.2.0.zip
cd neo4j-migrations-3.2.0
CLASSPATH_PREFIX=../neo4j-migrations-formats-adoc-3.2.0-all.jar \
bin/neo4j-migrations --password secret \
--location file:///path/to/neo4j/adoc-migrations \
infoWhich will result in:
neo4j@localhost:7687 (Neo4j/4.4.4)
Database: neo4j
+---------+---------------------------+---------+---------+----------------------------------------------+
| Version | Description | Type | State | Source |
+---------+---------------------------+---------+---------+----------------------------------------------+
| 1.0 | initial data | CYPHER | PENDING | initial_schema_draft.adoc#V1.0__initial_data |
| 1.2 | more data | CYPHER | PENDING | initial_schema_draft.adoc#V1.2__more_data |
| 2.0 | lets rock | CYPHER | PENDING | more_content.adoc#V2.0__lets_rock |
| 3.0 | We forgot the constraints | CATALOG | PENDING | V3.0__We_forgot_the_constraints.xml |
| 4.0 | Plain cypher | CYPHER | PENDING | V4.0__Plain_cypher.cypher |
+---------+---------------------------+---------+---------+----------------------------------------------+(Note: empty columns have been omitted for brevity.)
Markdown Support (Experimental)
What does it do?
When added to one of the supported use-case scenarios as an external library, it allows Neo4j-Migrations to discover Markdown files and use them as sources of Cypher statements for defining refactorings.
A Markdown based migration can have zero to many fenced code blocks with an id matching our versioning scheme and valid inline Cypher content. The block definition looks like this:
```id=V1.0__Create_initial_data
// Your Cypher based migrationHow to use it?
The extension is loaded via service loader. In a standard Spring Boot or Quarkus application you just need to add one additional dependency:
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-formats-markdown</artifactId>
<version>3.2.0</version>
</dependency>Or in case you fancy Gradle:
dependencies {
implementation 'eu.michael-simons.neo4j:neo4j-migrations-formats-markdown:3.2.0'
}And that’s all.
For the CLI, you should download the -all artifact from Maven Central: neo4j-migrations-formats-markdown-3.2.0-all.jar
This will work only with the JVM based CLI version, which is available here.
A full example looks like this:
curl -LO https://github.com/michael-simons/neo4j-migrations/releases/download/3.2.0/neo4j-migrations-3.2.0.zip
curl -LO https://repo.maven.apache.org/maven2/eu/michael-simons/neo4j/neo4j-migrations-formats-markdown/3.2.0/neo4j-migrations-formats-markdown-3.2.0-all.jar
unzip neo4j-migrations-3.2.0.zip
cd neo4j-migrations-3.2.0
CLASSPATH_PREFIX=../neo4j-migrations-formats-markdown-3.2.0-all.jar \
bin/neo4j-migrations --password secret \
--location file:///path/to/neo4j/markdown-migrations \
infoWhich will result in:
neo4j@localhost:7687 (Neo4j/4.4.8)
Database: neo4j
+---------+---------------------+--------+---------+--------------------------------------------+
| Version | Description | Type | State | Source |
+---------+---------------------+--------+---------+--------------------------------------------+
| 1.0 | initial data | CYPHER | PENDING | initial_schema_draft.md#V1.0__initial_data |
| 1.2 | more data | CYPHER | PENDING | initial_schema_draft.md#V1.2__more_data |
| 1.3 | something different | CYPHER | PENDING | more_content.md#V1.3__something_different |
+---------+---------------------+--------+---------+--------------------------------------------+(Note: empty columns have been omitted for brevity.)